

هنگامی که صحبت از ذخیره حجم زیادی از داده ها می شود، اصطلاحات دریاچه داده (Data Lake) و انبار داده (Data Warehouse) اغلب به طور تصادفی مورد استفاده قرار می گیرند. اغلب آنها به جای یکدیگر استفاده می شوند، اما در نحوه ساختار و پردازش داده ها کاملاً متفاوت هستند. اگر شما یک مهندس کلان داده هستید و تصمیم گیری در مورد استفاده از یک دریاچه داده یا یک انبار داده برای نیازهای سازمانی خود دشوار است، ما شما را تحت پوشش قرار داده ایم.
انبار داده (Data Warehouse) چیست؟
سیستمی که برای گزارش گیری و تجزیه و تحلیل داده ها استفاده می شود. انبارهای داده، مخازن مرکزی داده های یکپارچه از یک یا چند منبع متفاوت هستند. آنها داده های فعلی و تاریخی را در یک مکان ذخیره می کنند و برای ایجاد گزارش های تحلیلی برای کارگران در سراسر شرکت استفاده می شوند.” این بدان معنی است که انبار داده مجموعه ای از فناوری ها و اجزایی است که برای ذخیره داده ها برای برخی استفاده های استراتژیک استفاده می شود. داده ها جمع آوری می شوند. و در انبارهای داده از منابع متعدد برای ارائه بینش به داده های تجاری ذخیره می شود.
انبارهای داده داده های بسیار تغییر یافته و ساختار یافته را ذخیره می کنند که از پیش پردازش شده و برای خدمت به یک هدف خاص طراحی شده اند. داده ها معمولاً در انبار داده بارگذاری نمی شوند مگر اینکه یک مورد استفاده تعریف شده باشد. داده ها از انبارهای داده با استفاده از SQL پرس و جو می شوند.
معماری انبار داده
معماری انبار داده اساساً از لایه های زیر تشکیل شده است:
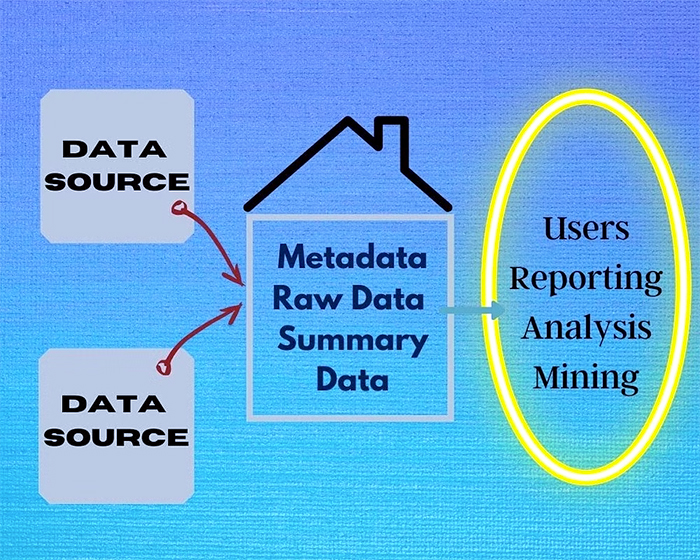
لایه منبع: انبارهای داده داده ها را از منابع متعدد و ناهمگن جمع آوری می کنند. دادههایی که باید جمعآوری شوند ممکن است ساختاریافته، بدون ساختار یا نیمه ساختاریافته باشند و باید از پایگاههای دادههای شرکتی یا قدیمی یا شاید حتی از سیستمهای اطلاعاتی خارج از کسبوکار بهدست آیند، اما همچنان مرتبط در نظر گرفته شوند.
ناحیه مرحله بندی: هنگامی که داده ها از منابع خارجی در لایه منبع جمع آوری می شوند، داده ها باید استخراج و پاک شوند. در انبارهای داده، انتظار می رود که داده ها مطابق با یک قالب خاص باشند. در این لایه، دادهها از قالب خام خود به قالبی تبدیل میشوند که مطابق با طرح مورد نیاز انبار داده باشد. ابزارهای ETL (استخراج، تبدیل، بارگذاری) داده ها را تبدیل، فیلتر و اعتبارسنجی می کنند. هر گونه ناهماهنگی یافت شده در داده ها حذف می شود و تمام شکاف هایی که می توان پر کرد برای اطمینان از حفظ یکپارچگی داده ها پر می شود.
بهترین در داده کاوی
←برای خرید کرک Tableau با تمام ویژگی ها کلیک کنید
لایه انبار داده: هنگامی که داده ها به فرمت مورد نیاز تبدیل شدند، در یک مخزن مرکزی ذخیره می شوند. لایه انبار داده شامل سیستم مدیریت پایگاه داده رابطه ای (RDBMS) است که شامل داده های پاک شده و ابرداده است که داده های مربوط به داده ها است. RDBMS میتواند مستقیماً از لایه انبار داده قابل دسترسی باشد یا در marts دادهای که برای بخشهای خاص سازمانی طراحی شدهاند ذخیره شود. فراداده حاوی اطلاعاتی مانند منبع داده، نحوه دسترسی به داده ها، کاربرانی است که ممکن است به داده ها نیاز داشته باشند و اطلاعات مربوط به طرحواره داده mart.
Data Marts: Data Marts ممکن است بر اساس بخشهای سازمانی تفکیک شده و اطلاعات مربوط به عملکرد خاصی از یک سازمان را ذخیره کند. Data marts شامل زیرمجموعه ای از داده ها در انبارهای داده است.
لایه تجزیه و تحلیل: لایه تجزیه و تحلیل از دسترسی به داده های یکپارچه برای برآوردن نیازهای تجاری آن پشتیبانی می کند. داده ها ممکن است برای صدور گزارش ها یا یافتن هر گونه الگوی پنهان در داده ها قابل دسترسی باشند. داده کاوی ممکن است برای تجزیه و تحلیل پویا اطلاعات یا شبیه سازی و تجزیه و تحلیل سناریوهای تجاری فرضی روی داده ها اعمال شود. برای پشتیبانی کارآمد از این امر، یک لایه تجزیه و تحلیل خوب باید دارای بهینه سازهای پرس و جو پیچیده، رابط کاربری گرافیکی که درک و استفاده آسان باشد و ناوبرهای اطلاعاتی داشته باشد.
دریاچه داده (Data Lake) چیست؟
یک سیستم یا مخزن دادهای که در قالب طبیعی/خام ذخیره میشود، معمولاً حبابهای شی یا فایلها. دریاچه داده، ذخیره واحدی از دادهها شامل نسخههای خام دادههای سیستم منبع، دادههای حسگر، دادههای اجتماعی و غیره است. یک دریاچه داده در شکل خام و پردازش نشده آن، شبیه به اینکه دریاچه ها دارای شاخه های متعددی هستند که به داخل آنها می ریزند.
دریاچه های داده از داده ها با فرمت های مختلف و طرحواره های ناشناخته مانند فایل های تخت، وبلاگ ها و ساختارهای دیگر پشتیبانی می کنند. داده های گرفته شده توسط یک دریاچه داده لزوماً اینطور نیست. باید فورا مورد استفاده قرار گیرد اما ممکن است برای استفاده در آینده در دریاچه داده ذخیره شود. از آنجایی که مقادیر زیادی داده در یک دریاچه داده وجود دارد، برای ردیابی عملکرد تحلیلی و یکپارچه سازی داده ها ایده آل است. داده ها در دریاچه های داده ممکن است با استفاده از SQL قابل دسترسی باشند. , Python, R, Spark یا سایر ابزارهای جستجوی داده.
معماری دریاچه داده
معماری دریاچه دادهها روشهای مختلف جستجو و تجزیه و تحلیل را در بر میگیرد تا به سازمانها کمک کند تا بینشهای معناداری را از حجم زیادی از دادهها به دست آورند. دریاچه های داده دارای معماری مسطح برای پاسخگویی به طیف گسترده ای از نیازهای تجاری هستند. معماری دریاچه داده از لایه های زیر تشکیل شده است:
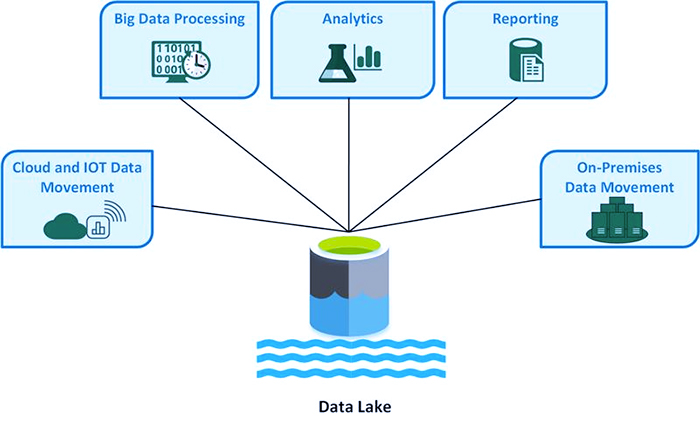
لایه جذب: در این لایه داده ها از منابع مختلف بارگذاری می شوند. نوع داده ای که در دریاچه داده جمع آوری می شود می تواند ساختار یافته، نیمه ساختاریافته یا بدون ساختار باشد. همچنین میتوان آن را به صورت دستهای یا قالب پخش بلادرنگ در دریاچه داده بارگذاری کرد.
لایه ذخیره سازی: این یک مخزن متمرکز است که در آن تمام داده های بارگذاری شده در دریاچه داده ذخیره می شود. HDFS یک راه حل مقرون به صرفه برای لایه ذخیره سازی است زیرا از ذخیره سازی و جستجوی داده های ساختاریافته و بدون ساختار پشتیبانی می کند. لایه ذخیره سازی را می توان منطقه فرود برای تمام داده هایی که قرار است در دریاچه داده ذخیره شود در نظر گرفت.
لایه عملیاتی یکپارچه: این لایه مدیریت و امنیت دریاچه داده را کنترل می کند. اگرچه درصد کمی از کاربران از دریاچه داده استفاده می کنند، ممکن است حاوی داده های محرمانه باشد و از این رو امنیت لایه باید حفظ شود. این لایه از ممیزی و مدیریت داده پشتیبانی می کند، که در آن نظارت دقیقی بر روی داده های بارگذاری شده در دریاچه داده و هرگونه تغییر در عناصر داده دریاچه داده انجام می شود. لایه عملیات همچنین مدیریت گردش کار و مهارت داده ها در دریاچه داده را مدیریت می کند.
بیشتر بخوانید
←دریاچه داده (data lake) چیست؟
لایه تقطیر: زمانی که داده ها برای پردازش مورد نیاز هستند، داده ها باید تمیز و فیلتر شوند همچنین لایه تقطیر امکان برداشت داده ها از لایه ذخیره سازی و تبدیل آن به داده های ساختار یافته را برای تجزیه و تحلیل آسان تر می کند.
لایه تحلیل و بینش: این لایه از اجرای الگوریتم های تحلیلی و محاسبات روی داده های موجود در دریاچه داده پشتیبانی می کند. باید برای پشتیبانی از پرسشهایی ساخته شود که میتوانند با دادههای همزمان، تعاملی و دستهای کار کنند. بینش های سیستم ممکن است برای پردازش داده ها به روش های مختلف استفاده شود. این لایه باید از پرس و جوهای SQL و NoSQL پشتیبانی کند. حتی ممکن است از برگه های اکسل برای تجزیه و تحلیل داده ها استفاده شود.
شرکت ironSource را در نظر بگیرید، یک پلتفرم تبلیغاتی ویدیویی پیشرو که شامل یکی از بزرگترین شبکه های ویدئویی درون برنامه ای در صنعت است. ironSource باید حجم وسیعی از داده ها را از میلیون ها دستگاه جمع آوری و ذخیره کند. ironSource شروع به استفاده از Upsolver به عنوان دریاچه داده خود برای ذخیره داده های خام رویداد کرد.
جریان های کافکا، متشکل از 500000 رویداد در ثانیه، وارد Upsolver می شوند و در AWS S3 ذخیره می شوند. Upsolver دارای ابزارهایی برای آماده سازی خودکار داده ها برای مصرف در Athena است، از جمله فشرده سازی، پارتیشن بندی فشرده سازی و مدیریت و ایجاد جداول در کاتالوگ داده چسب AWS. ironSource از Upsolver برای فیلتر کردن دادهها و نوشتن آن در Redshift برای ساخت داشبورد در Tableau و ارسال دادهها به Athena برای تجزیه و تحلیل پرس و جوی موقت استفاده میکند.
مقایسه دریاچه داده (Data Lake) و انبار داده (Data Warehouse)
ذخیره سازی
دریاچه های داده برای ذخیره سازی کم هزینه طراحی شده اند، بر خلاف انبارهای داده که یک انتخاب گران قیمت برای ذخیره سازی حجم زیاد داده ها هستند. یک Data Lake تمام فرمت های داده را بدون توجه به منبع و ساختار آن حفظ می کند. داده ها به شکل خام در یک دریاچه داده ذخیره می شوند و تنها زمانی تبدیل می شوند که استفاده شوند. از طرف دیگر، یک انبار داده، داده هایی را ذخیره می کند که پس از استخراج از سیستم های تراکنش، پاکسازی و تبدیل می شوند.
یک انبار داده عموماً داده هایی را ذخیره نمی کند که هدف خاصی را دنبال نمی کنند یا داده هایی که نمی توانند به یک سؤال تجاری خاص پاسخ دهند. دریاچه داده همه دادهها را حفظ میکند، از جمله دادههایی که در حال حاضر استفاده میشوند، دادههایی که ممکن است مورد استفاده قرار گیرند و حتی دادههایی که ممکن است هرگز واقعاً مورد استفاده قرار نگیرند، اما برخی فرضها وجود دارد که ممکن است در آینده مفید باشد. ذخیره سازی داده ها در انبارهای داده معمولاً گران تر و وقت گیرتر است زیرا باید نسبت به داده های ذخیره شده در دریاچه های داده پردازش شود.
در دریاچه های داده، طرح واره توسط پرس و جو اعمال می شود و آنها طرحی دقیق مانند انبارهای داده ندارند. بارگذاری داده ها در دریاچه داده نسبتاً آسان تر است، اما نوشتن پرس و جوها پیچیده است، بنابراین بازیابی داده ها از یک دریاچه داده در مقایسه با یک انبار داده زمان بر است.
گرفتن داده ها
دریاچه های داده داده های خام و پردازش نشده را می گیرند، در حالی که انبارهای داده داده های پردازش شده را می گیرند. داده ها در دریاچه های داده می توانند از همه فرمت ها اعم از ساختاریافته، بدون ساختار و نیمه ساختار یافته باشند. دریاچه های داده همه داده ها را صرف نظر از منبع آنها می گیرند. انبارهای داده اطلاعات ساختار یافته را جمع آوری کرده و در طرحواره های خاصی که برای انبار داده تعریف شده اند ذخیره می کنند.
جدول زمانی داده ها
دریاچه های داده همه داده ها را حفظ می کنند، از جمله داده هایی که در حال حاضر استفاده نمی شوند. از این رو، داده ها را می توان برای همیشه در دریاچه های داده نگهداری کرد تا داده ها را بیشتر تجزیه و تحلیل کند.
به دادههای خام اجازه داده میشود تا به دریاچه دادهها سرازیر شوند، گاهی اوقات بدون استفاده فوری. این داده ها برای استفاده احتمالی در آینده حفظ می شوند. هنگامی که چنین زمانی فرا می رسد، داده ها به سادگی از دریاچه داده قابل دسترسی هستند. در یک انبار داده، داده ها به طور کلی پردازش می شوند. منبع دادههای جمعآوریشده به دقت تجزیه و تحلیل میشود و برای خدمت به یک هدف خاص در یک زمان خاص استفاده میشود.
پردازش داده ها
دریاچه های داده را می توان به عنوان ابزار ELT (Extract، Load، Transform) استفاده کرد، در حالی که انبارهای داده به عنوان ابزار ETL (Extract، Transform، Load) عمل می کنند. Data Lakes و انبارهای داده در سیستم های OLAP (پردازش تحلیلی آنلاین) و سیستم های OLTP (پردازش معاملات آنلاین) استفاده می شوند. دریاچه های داده به کاربران اجازه می دهند تا قبل از پاکسازی و تبدیل به داده های خام و پردازش نشده دسترسی داشته باشند، در حالی که انبارهای داده می توانند از طریق داده های پردازش شده، بینش هایی را در مورد سؤالات تجاری خاص به کاربران ارائه دهند.
موقعیت یابی طرحواره
انبارهای داده از طرحی بر روی استراتژی نوشتن برای پردازش داده پیروی می کنند بر خلاف دریاچه های داده که از طرحی بر روی استراتژی خواندن پیروی می کنند. دریاچه های داده دارای ساختار “شما در خواندن” هستند، به این معنی که طرح واره در دریاچه های داده پس از ذخیره داده ها تعریف می شود. این امر باعث میشود که دادهها آسان شود، زیرا دادهها را میتوان از یک منبع بدون در نظر گرفتن ماهیت دادهها گرفت.
همچنین هنگامی که داده برای پردازش بیشتر مورد نیاز است اما در زمان پردازش داده ها به کار بیشتری نیاز دارد، با روش دستکاری داده ها انعطاف پذیری بالایی را ارائه می دهد. در یک انبار داده، ساختار طرحواره “Schema-on-Write” است، به این معنی که طرحواره معمولاً قبل از ذخیره شدن داده ها تعریف می شود. در نتیجه، در حین جمعآوری و ذخیره دادهها در انبار داده، کار بیشتری وجود دارد، اما در صورت نیاز به تجزیه و تحلیل بیشتر، عملکرد و امنیت بیشتری وجود دارد.
←برای خرید کرک Tableau با تمام ویژگی ها کلیک کنید
وظایف
دریاچه های داده شامل مجموعه ای از داده های مورد استفاده و داده هایی هستند که ممکن است در آینده مورد استفاده قرار گیرند. تنوع دادهها در دریاچه داده، انجام تجزیه و تحلیل دادهها بر روی حجم زیادی از دادهها را برای کاربرانی که میخواهند بینش جدیدی نسبت به دادهها به دست آورند، بسیار مفید است. این اجازه می دهد تا کاربران به داده ها قبل از تبدیل و پاکسازی دسترسی داشته باشند. انبارهای داده عمدتاً حاوی دادههایی هستند که میتوانند بینشهایی را برای برخی از سؤالات تجاری از پیش تعریفشده ارائه دهند و عمدتاً برای تولید گزارشهای خاص برای کاربران عملیاتی استفاده میشوند.
کاربران
دریاچه داده برای کاربرانی که به داده ها برای تجزیه و تحلیل عمیق نیاز دارند ایده آل است. از آنجایی که داده ها حجم زیادی خواهند داشت و ممکن است از داده های ساختاریافته، بدون ساختار و نیمه ساختاریافته تشکیل شوند، برای کاربرانی که دارای ابزارهای تحلیلی پیشرفته برای تجزیه و تحلیل داده ها هستند، از جمله مهندسان داده، دانشمندان داده و مهندسان تجزیه و تحلیل داده، ایده آل است.
آنها می توانند از ابزارهای کلان داده خود برای کار بر روی مجموعه داده های بزرگ و متنوع برای انجام هر گونه تجزیه و تحلیل و پردازش مورد نیاز استفاده کنند. انبار داده متشکل از داده هایی است که تبدیل و پاکسازی می شوند و برای کاربران عملیاتی مناسب تر است زیرا استفاده و درک داده ها آسان است. انبارهای داده برای پاسخ به سؤالات خاص کسب و کار و داشتن اطلاعاتی در مورد داده ها مانند شاخص های کلیدی عملکرد ساخته شده اند.
مزایای
دریاچه های داده، داده های خام و پردازش نشده را بدون در نظر گرفتن منبع داده ها ذخیره می کنند. این امکان ذخیره سازی داده ها را آسان می کند زیرا داده ها را می توان فقط از یک منبع گرفته و برای مدت طولانی در دریاچه های داده ذخیره کرد.
از آنجایی که دریاچه های داده داده هایی را ذخیره می کنند که در حال حاضر مورد استفاده نیستند اما ممکن است در زمان بعدی مورد نیاز باشند، منبع عالی برای تجزیه و تحلیل داده ها هستند. علاوه بر این، دریاچههای داده با هر تغییری در دادههای ورودی بسیار سازگار هستند، زیرا هیچ طرح از پیش تعریفشدهای برای ذخیره دادهها در دریاچه داده وجود ندارد.
از آنجایی که انبارهای داده داده های پاک شده و تبدیل شده را ذخیره می کنند، برای کاربران عملیاتی که نیازی به غواصی عمیق در داده ها ندارند و فقط به داده ها برای استفاده خود نیاز دارند، سودمند است. داده ها قالبی هستند که به راحتی قابل درک است. اکثر کاربران یک سازمان، کاربران عملیاتی هستند و فقط به گزارش ها و معیارهای کلیدی عملکرد نیاز دارند. حتی در مواردی که پردازش بیشتری برای داده ها مورد نیاز است زیرا قبلاً پاک شده است، کار با آن آسان تر است.
معایب
در دریاچه های داده، از آنجایی که داده ها به شکل خام خود نگهداری می شوند، پس از آماده شدن برای استفاده باید تبدیل شوند.
از آنجایی که مقادیر زیادی از داده ها به طور مداوم در یک دریاچه داده نگهداری می شوند. ممکن است داده های اضافی و نامربوط وجود داشته باشد. زمانی که اطلاعات خاصی مورد نیاز است، مرتب کردن دادهها دشوار میشود.
در انبارهای داده، یک مسئله اصلی مشکلی است که هنگام تلاش برای ایجاد تغییرات در داده ها یا هر تغییری در داده های جریان یافته به انبار داده با آن مواجه می شود.
انبارهای داده معمولاً طرحی از پیش تعریف شده دارند که داده ها باید از آن پیروی کنند. تغییرات در داده ها ممکن است نیاز به اصلاحات در طرحواره داشته باشد، که می تواند منجر به بازسازی و بازسازی شود.
جدول مقایسه
| دریاچه داده (Data Lake) | انبار داده (Data Warehouse) |
| دریاچه های داده تمام داده ها را صرف نظر از منبع و ساختار حفظ می کنند. | منبع داده های ذخیره شده در یک انبار داده قبل از ذخیره داده ها در انبار داده به دقت تجزیه و تحلیل می شود. |
| Data Lakes داده های ساخت یافته، بدون ساختار و نیمه ساختار یافته را ذخیره می کند. | انبارهای داده فقط داده های ساختار یافته را در یک RDBMS ذخیره می کنند، جایی که داده ها را می توان با استفاده از SQL پرس و جو کرد. |
| داده های موجود در دریاچه های داده باید قبل از استفاده برای تجزیه و تحلیل، پاکسازی و تبدیل شوند. | از آنجایی که دادههای موجود در انبارهای داده قبلاً تمیز و تبدیل شدهاند، میتوان مستقیماً از آن برای پردازش بیشتر استفاده کرد. |
| دریاچه های داده از Schema-on-Read پیروی می کنند. | انبارهای داده از Schema-on-Write پیروی می کنند. |
| دادهها در دریاچههای داده ممکن است در حال حاضر در حال استفاده باشند یا در دریاچه داده برای برخی استفادههای احتمالی در آینده ذخیره شوند. |
داده ها در انبار داده بارگذاری نمی شوند مگر اینکه برای هدف خاصی مورد نیاز باشند. |
| متخصصانی که باید تجزیه و تحلیل عمیق انجام دهند و ابزارهای تحلیلی را در اختیار دارند، کسانی هستند که از داده ها در دریاچه داده استفاده می کنند. | انبارهای داده عمدتاً برای کاربران عملیاتی هستند که به برخی گزارش ها یا شاخص های عملکرد کلیدی از داده ها نیاز دارند. |
| حجم وسیعی از داده ها در یک دریاچه داده برای هر تجزیه و تحلیل داده ای که باید انجام شود به خوبی استفاده می شود. | از آنجایی که داده ها قبلاً در یک انبار داده ساختار یافته اند، استفاده و درک آن برای کاربران عملیاتی آسان است. |
| دریاچه های داده به راحتی با تغییرات سازگار می شوند زیرا هیچ طرح از پیش تعریف شده ای وجود ندارد که داده ها باید از آن پیروی کنند. | تغییرات در انبار داده ممکن است نیاز به کار مجدد داشته باشد و همچنین بسیار وقت گیر باشد. |
آینده داده های بزرگ
پاسخ به این سوال این است که بستگی به مورد استفاده تجاری در عمل دارد.
به عنوان مثال، اگر برای یک شرکت رسانههای اجتماعی کار میکنید، معمولاً دادهها به شکل تصاویر و اسناد با حداقل دادههای ساختاریافته (بدون ساختار) هستند. بنابراین دریاچه داده میتواند انتخاب خوبی باشد.
با این حال، اگر برای یک شرکت تجارت الکترونیک کار میکنید. این شرکتها دارای بخشهای متعددی هستند که دادهها را تولید میکنند و انبارهای داده میتوانند انتخاب خوبی برای دریافت خلاصهای از همه آن دادهها باشند.
کرک تبلو
اغلب هنگام ساخت خطوط لوله داده، باید از هر دو گزینه ذخیره سازی برای نتایج بهینه استفاده کنید.
بهترین رویکرد همیشه این است که ترکیبی از این دو داشته باشیم و همیشه بحثی بین data lake و data warehouse نیست.
می توانید از دریاچه داده (انتخاب اقتصادی) برای تجزیه و تحلیل داده های اکتشافی استفاده کنید ، از انبار داده برای گزارش دهی موثر و کارآمد استفاده کنید.
اگر میخواهید تجربه عملی در درک تفاوتهای آنها کسب کنید یا میخواهید نحوه استفاده از دریاچه داده یا انبار داده را در پروژه بعدی خود بیاموزید.
پروژههای Big Data را با کدهای قابل استفاده مجدد، ویدیوهای هدایتشده، مجموعه دادههای قابل دانلود و مستندات حلشده کاوش کنید تا در مسیر یادگیری به شما کمک کنند.
←برای خرید کرک Tableau با تمام ویژگی ها کلیک کنید
مقاله های مرتبط:
1- تفاوت و مقایسه هوش تجاری (BI) و انبار داده
2-توسعه پایگاه داده استاندارد SQL Server
3-چرا Data Structures یا ساختارهای داده مهم هستند؟
4-چرا Data Structures یا ساختارهای داده مهم هستند؟
5-تفاوت های داده های طبقه بندی شده (Categorical Data) در مقابل داده های عددی (Numerical Data)
6-تفاوت های داده های طبقه بندی شده (Categorical Data) در مقابل داده های عددی (Numerical Data)
8-داده های طبقه بندی شده (Categorical Data) چیست و چه ویژگی هایی دارد
9-چالش ها و نحوه مدیریت داده های همه جا حاضر یا Ubiquitous Data
10-معرفی انواع مدل های داده ای یا Data Model
11-ردیابی داده ها یا Data Tracking چیست و چه فایده ای دارد؟
13-توضیح و تفاوت های داده های سخت (Hard Data) در مقابل داده های نرم (Soft Data)
14-تحلیل داده های کسب و کار با هوش تجاری