

ابزار Hive چیست؟
Hive که با نام Apache Hive نیز شناخته می شود یکی از ابزارهای مبتنی بر زیرساخت انبار داده است که برای پردازش داده های ساخت یافته در Hadoop استفاده می شود.
این نرمافزاری است که تسهیلات متعددی مانند نوشتن، خواندن و مدیریت حجم زیادی از دادهها را که در فضای ذخیرهسازی توزیع شده با استفاده از SQL وجود دارد، فراهم میکند.
Hadoop به انجام عملیاتی مانند تجزیه و تحلیل داده ها، خلاصه سازی داده ها و پرس و جوی داده ها کمک می کند. HiveQL زبان پرس و جو است .
برای ترجمه پرس و جوهای SQL به jobs mapreduce استفاده می کند. Hive به طور خاص برای کارهای دسته ای استفاده می شود.
Hive که با نام Apache Hive نیز شناخته می شود یکی از ابزارهای مبتنی بر زیرساخت انبار داده است که برای پردازش داده های ساخت یافته در Hadoop استفاده می شود.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
چرا از Hive استفاده کنیم؟
Apache Hive برای انجام عملکردهایی مانند تجزیه و تحلیل داده ها، پرس و جو و خلاصه سازی استفاده می شود.
این ابزار همچنین به بهبود بهرهوری توسعهدهندگان در مورد هزینههای مورد نیاز به دلیل افزایش تاخیر کمک میکند.
هیوا یکی از فناوریها یا ابزارهایی است که در مقایسه با سایر سیستمهای SQL برجسته و در پایگاههای داده پیادهسازی شده است.
همچنین شامل توابع دیگری است که توسط کاربر تعریف شده است که به ارائه راه های موثر برای حل مسائل کمک می کند. اتصال کوئری های Hive به بسته های Hadoop مانند RHipe، RHive بسیار آسان است.
هیوا معمولاً به یک سیستم خاص اشاره می کند که به گزارش و تجزیه و تحلیل داده ها کمک می کند.
هدف اولیه شناسایی و ارائه اطلاعات معنادار همراه با پیشنهادات و نتیجه گیری هایی است که به بهبود سازمان کمک می کند.
رویکردها و جنبههای زیادی وجود دارد که باید همراه با برخی تکنیکهای پویا در هنگام انجام تجزیه و تحلیل دادهها گنجانده شوند.
هیوا همچنین به کاربران خود اجازه می دهد تا در هر زمان به داده ها دسترسی داشته باشند.
همچنین زمان پاسخ را افزایش می دهد که چیزی نیست جز زمانی که یک واحد عملکردی بر اساس یک ورودی خاص واکنش نشان می دهد.
در مقایسه با سایر پرس و جوها، hive زمان پاسخ سریع تری دارد و همچنین بسیار انعطاف پذیر است.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
Hive چگونه کار می کند؟
معمولاً به منظور ایجاد انعطاف پذیری برای غیر برنامه نویسان برای آشنایی با زبان برنامه نویسی SQL و همچنین ایجاد توانایی آنها در کار با حجم زیادی از داده ها ایجاد می شود.
همه اینها از طریق یک رابط شبیه به SQL به نام HiveQL انجام می شود. در تایمز سنتی، سیستمهای پایگاهداده رابطهای معمولاً برای پردازش حجمهای کوچک داده تا مجموعههای داده متوسط طراحی شدهاند.
اما قادر به پردازش حجم زیادی از دادهها مانند پتابایت داده نیستند. Hive از پردازش دسته ای استفاده می کند که به پردازش حجم داده ها به صورت موازی در یک پایگاه داده توزیع شده کمک می کند.
هیوا مسئول تبدیل پرسوجوهای Hive SQL به mapreduce است که در چارچوب زمانبندی کار توزیعشده که به عنوان ناوبر منبع دیگری نامیده میشود، اجرا میشود که اغلب به نام YARN نامیده میشود.
مسئول به دست آوردن داده هایی است که در فضای ذخیره سازی توزیع شده مانند HDFS ذخیره می شود. بزرگراه مسئول ذخیره پایگاه داده و ابرداده در یک متا استور است که معمولاً یک پایگاه داده یا ذخیره فایل پشتیبان است که به کشف و انتزاع آسان داده ها کمک می کند.
هیوا همچنین شامل یک جدول و یک لایه مدیریت ذخیره سازی به نام HCatalog است که به خواندن داده ها از -metastore Hive کمک می کند و همچنین یکپارچگی بین mapreduce، hive و Apache pig را فراهم می کند. HCatalog مسئول اجازه دادن به mapreduce و pig برای استفاده از ساختارهای داده ای است که به عنوان Hive استفاده می شود.
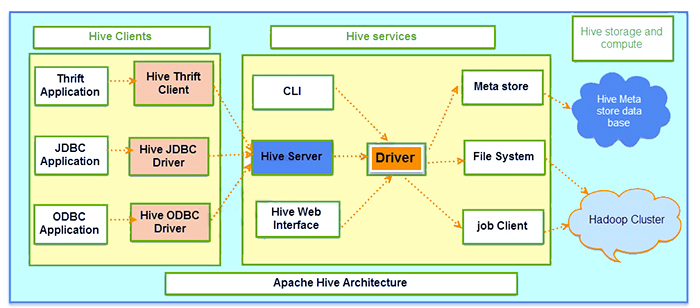
معماری Hive شامل سه جزء اصلی :
- مشتریان
- خدمات
- ذخیره سازی و محاسبات
در زیر تصویری از معماری Hive نشان داده شده است.
۱- مشتریان Hive :
درایورهای مستقیم مختلفی وجود دارند که توسط high برای اهداف ارتباطی ارائه شده اند که می توانند در انواع مختلف برنامه ها پیاده سازی شوند. بگذارید بگوییم که این یک برنامه کاربردی مبتنی بر صرفه جویی است، سپس مشتری صرفه جویی را برای اهداف ارتباطی ارائه می دهد.
درایورهای JDBC برای برنامه های کاربردی مرتبط با جاوا استفاده می شوند. همه این نوع و درایورها دوباره با سرور Hive که در سرویس های Hive وجود دارد ارتباط برقرار می کنند.
۲- خدمات Hive :
خدمات Hive برای ایجاد تعامل مشتری با کندو استفاده می شود. اگر مشتری خاصی بخواهد عملیات مربوط به پرس و جو را انجام دهد، باید از طریق خدمات کندو ارتباط برقرار کند.
در hive، این یک خط فرمان است که به عنوان سرویس ارتفاع برای عملیات مبتنی بر زبان تعریف داده عمل می کند. ارتباط با رانندگان در سرور Hive و همراه با درایور اصلی به سرویس های Hive وجود خواهد داشت.
درایوری که در بالاترین خدمات وجود دارد به عنوان درایور اصلی نامیده می شود که در برقراری ارتباط با انواع برنامه های مبتنی بر مشتری استفاده می شود.
۳- ذخیره سازی و محاسبات Hive :
خدمات Hive شامل سیستم فایل، فروشگاه متا، سرویس گیرنده شغلی است که با بالاترین فضای ذخیره سازی ارتباط برقرار می کند و مجموعه اقدامات زیر را انجام می دهد.
اطلاعات فراداده ارائه شده در قالب جداول ایجاد شده در Hive در پایگاه داده metastore Hive ذخیره می شود.
تمام داده ها و نتایج پرس و جو که در جداول نشان داده شده اند در خوشه در HDFS ذخیره می شوند.
ویژگی ها ابزار Hive
- ابزاری است که برای مدیریت و پرس و جوی داده ها طراحی شده است که فرمت ساختار آن در قالب جداول است.
- بسیار سریع و مقیاس پذیر است.
- پردازش داده ها به سیستم فایل توزیع شده Hadoop منتقل می شود در حالی که طرحواره در پایگاه داده ذخیره می شود.
- تمام پایگاه های داده و جداول ابتدا ایجاد می شوند و سپس بارگذاری داده ها افزایش می یابد که در جداول مناسب نمایش داده می شود.
- قادر است پشتیبانی گسترده خود را از طریق فرمت های فایل مانند فایل متنی، فایل rC، فایل توالی، ORC ارائه دهد.
- به عنوان زبان الهام گرفته از SQL در نظر گرفته می شود که پیچیدگی برنامه نویسی mapreduce را کاهش می دهد. از مفاهیم آشنا استفاده می کند که معمولاً در پایگاه داده های رابطه ای مانند ردیف ها، ستون ها، جداول، طرحواره و غیره نمایش داده می شوند.
- تفاوت اصلی بین زبان پرس و جو Hive و SQL این است که Hive به جای استفاده از پایگاه داده سنتی، کوئری ها را در زیرساخت Hadoop اجرا می کند.
- از bucket ها و پارتیشن ها برای بازیابی سریعتر و ساده تر داده ها پشتیبانی می کند.
- همچنین از طریق توابع تعریف شده توسط کاربر سفارشی که به انجام وظایفی مانند فیلتر کردن و تمیز کردن داده ها کمک می کند، پشتیبانی گسترده ای را ارائه می دهد. توابع تعریف شده توسط کاربر را می توان بر اساس الزامات برنامه نویسان تعریف کرد.
چگونه داده ها درHive جریان می یابد؟
- تحلیلگر داده شخصی است که مسئول اجرای یک پرس و جو در رابط کاربری است.
- مسئولیت تعامل با کامپایلر کوئری و همچنین بازیابی پلن بر عهده راننده است. معمولاً شامل اطلاعات متا داده و فرآیند اجرای پرس و جو است که برای اجرای پرس و جو استفاده می شود. راننده همچنین query e را برای بررسی تصادفی الزامات و نحو ارسال می کند.
- زمان آن است که کامپایلر برنامه کاری را ایجاد کند که باید اجرا شود و همچنین با metastore برای انجام بازیابی درخواست ابرداده ارتباط برقرار می کند.
- metastore مسئول ارسال اطلاعات به کامپایلر است.
- سپس یک کامپایلر در طرح اجرای پرس و جو قابل اعتماد خواهد بود که به درایور منتقل می شود.
- driver مسئول ارسال طرح اجرا به موتور اجرا خواهد بود.
- موتور اجرا مسئول پردازش پرس و جو است که به عنوان یک رابط یا یک پل بین Hadoop و hive عمل می کند. این فرآیند در mapreduce اجرا خواهد شد. سپس موتور اجرا کار آنها را به ردیاب شغلی خود ارسال می کند، نام را در نام گره شناسایی می کند و سپس آن را به ردیاب وظیفه که در گره تاریخ وجود دارد اختصاص می دهد. در حالی که همه این عملکردها در حال انجام هستند، موتور اجرایی عملیات دادهای را که در فروشگاه متا وجود دارد را نیز اجرا میکند.
- تمام نتایج از گره های داده بازیابی خواهد شد.
- پس از به دست آمدن نتایج و ارسال به موتور اجرا، نتایج به درایور و سپس رابط کاربری جلویی ارسال می شود.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
مقاله های مرتبط: