

داده کاوی (Data Mining) فرآیند یافتن الگوها و روابط در مقادیر زیاد داده است. این یک تکنیک پیشرفته تجزیه و تحلیل داده است که یادگیری ماشینی و هوش مصنوعی را برای استخراج اطلاعات مفید ترکیب میکند، که به کسبوکارها کمک میکند تا درباره نیازهای مشتریان، افزایش درآمد، کاهش هزینهها، بهبود روابط با مشتری و موارد دیگر اطلاعات بیشتری کسب کنند.
در زیر، ما فهرستی از 10 ابزار برتر دادهکاوی – هم منبع باز و هم راهحلهای نرمافزار به عنوان سرویس (SaaS) را قرار دادهایم تا بتوانید اطلاعات مفیدی در مورد مشتریان و عملکرد کلی کسبوکار خود به دست آورید.
10 ابزار برتر داده کاوی
- MonkeyLearn – ابزارهای متن کاوی بدون کد
- RapidMiner – جریان کار یا داده کاوی را در پایتون بکشید و رها کنید
- Oracle Data Mining – مدل های پیش بینی داده کاوی
- IBM SPSS Modeler – یک پلت فرم تجزیه و تحلیل پیش بینی برای دانشمندان داده
- Weka – نرم افزار منبع باز برای داده کاوی
- Knime – اجزای از پیش ساخته شده برای پروژه های داده کاوی
- H2O – کتابخانه منبع باز ارائه داده کاوی در پایتون
- Orange – جعبه ابزار داده کاوی منبع باز
- Apache Mahout – ایده آل برای داده کاوی پیچیده و در مقیاس بزرگ
- SAS Enterprise Miner – حل مشکلات تجاری با داده کاوی
1- MonkeyLearn
MonkeyLearn یک پلت فرم یادگیری ماشینی است که در متن کاوی تخصص دارد. موجود در یک رابط کاربر پسند، می توانید به راحتی MonkeyLearn را با ابزارهای موجود خود برای انجام داده کاوی در زمان واقعی ادغام کنید.
فوراً با مدلهای متنکاوی از پیش آموزشدیدهشده مانند این تحلیلگر احساسات در زیر شروع کنید، یا یک راهحل سفارشی برای رفع نیازهای تجاری خاصتر بسازید.
MonkeyLearn از وظایف مختلف داده کاوی، از شناسایی موضوعات، احساسات و هدف گرفته تا استخراج کلمات کلیدی و موجودیت های نامگذاری شده، پشتیبانی می کند.
ابزارهای متن کاوی MonkeyLearn در حال حاضر برای خودکارسازی برچسبگذاری بلیط و مسیریابی در پشتیبانی مشتری، شناسایی خودکار بازخورد منفی در رسانههای اجتماعی، و ارائه بینشهای دقیقی که منجر به تصمیمگیری بهتر میشود، استفاده میشود.
با MonkeyLearn، میتوانید دادههای تجزیهوتحلیلشده خود را به MonkeyLearn Studio، یک داشبورد تجسم دادههای قابل تنظیم که تشخیص روندها و الگوهای دادههای شما را آسانتر میکند، متصل کنید.
به برنامه ها و قیمت MonkeyLearn نگاهی بیندازید. یا یک نسخه نمایشی را برنامه ریزی کنید تا بدانید ابزارهای متن کاوی چه کاری می توانند برای شما انجام دهند.
←برای خرید لایسنس Tableau با تمام ویژگی ها کلیک کنید
2- RapidMiner
RapidMiner یک پلت فرم رایگان منبع باز علوم داده است که دارای صدها الگوریتم برای آماده سازی داده ها، یادگیری ماشینی، یادگیری عمیق، متن کاوی و تجزیه و تحلیل پیش بینی کننده است.
رابط کشیدن و رها کردن و مدلهای از پیش ساخته شده آن به غیربرنامهنویسان اجازه میدهد تا به طور مستقیم گردشهای کاری پیشبینیکننده را برای موارد استفاده خاص، مانند تشخیص تقلب و ریزش مشتری ایجاد کنند. در همین حال، برنامه نویسان می توانند از پسوندهای R و Python RapidMiner برای تنظیم داده کاوی خود استفاده کنند.
هنگامی که گردش کار خود را ایجاد کردید و داده های خود را تجزیه و تحلیل کردید، نتایج خود را در RapidMiner Studio تجسم کنید تا به شما کمک کند الگوها، نقاط دورافتاده و روندها را در داده های خود تشخیص دهید.
آخرین اما نه کم اهمیت، این پلتفرم دارای یک جامعه بزرگ و مشتاق از کاربران است که همیشه آماده کمک هستند.
3- Oracle Data Mining
داده کاوی Oracle جزءی از Oracle Advanced Analytics است که به تحلیلگران داده امکان می دهد مدل های پیش بینی را بسازند و پیاده سازی کنند. این شامل چندین الگوریتم داده کاوی برای کارهایی مانند طبقه بندی، رگرسیون، تشخیص ناهنجاری، پیش بینی و موارد دیگر است.
با داده کاوی اوراکل، می توانید مدل هایی بسازید که به شما کمک می کند رفتار مشتری را پیش بینی کنید، پروفایل های مشتری را تقسیم بندی کنید، کلاهبرداری را شناسایی کنید و بهترین مشتریان بالقوه را شناسایی کنید. توسعهدهندگان میتوانند از Java API برای ادغام این مدلها در برنامههای کاربردی هوش تجاری استفاده کنند تا به آنها در کشف روندها و الگوهای جدید کمک کند.
4- IBM SPSS Modeler
IBM SPSS Modeler یک راه حل داده کاوی است که به دانشمندان داده اجازه می دهد تا روند داده کاوی را تسریع و تجسم کنند. حتی کاربرانی که تجربه برنامه نویسی کمی دارند یا اصلاً تجربه ندارند، می توانند از الگوریتم های پیشرفته برای ساخت مدل های پیش بینی در یک رابط کشیدن و رها کردن استفاده کنند.
با مدلساز SPSS IBM، تیمهای علم داده میتوانند حجم زیادی از دادهها را از منابع متعدد وارد کرده و آنها را دوباره مرتب کنند تا روندها و الگوها را کشف کنند. نسخه استاندارد این ابزار با داده های عددی از صفحات گسترده و پایگاه های داده رابطه ای کار می کند. برای افزودن قابلیت های تجزیه و تحلیل متن، باید نسخه پریمیوم را نصب کنید.
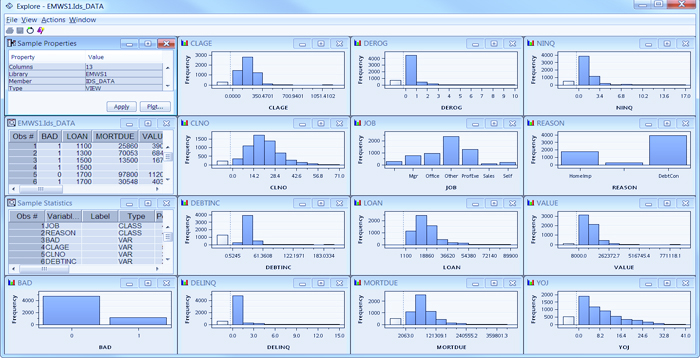
5- Weka
Weka یک نرم افزار یادگیری ماشین منبع باز با مجموعه گسترده ای از الگوریتم ها برای داده کاوی است. این توسط دانشگاه Waikato در نیوزیلند توسعه یافته است و با جاوا اسکریپت نوشته شده است.
از وظایف مختلف داده کاوی مانند پیش پردازش، طبقه بندی، رگرسیون، خوشه بندی و تجسم در یک رابط گرافیکی پشتیبانی می کند که استفاده از آن را آسان می کند. برای هر یک از این وظایف، Weka الگوریتمهای یادگیری ماشینی داخلی را ارائه میکند که به شما امکان میدهد ایدههای خود را به سرعت آزمایش کنید و مدلها را بدون نوشتن کد اجرا کنید. برای استفاده کامل از این، باید دانش کاملی از الگوریتمهای مختلف موجود داشته باشید تا بتوانید الگوریتم مناسب را برای مورد خاص خود انتخاب کنید.
6- Knime
KNIME یک پلت فرم رایگان و منبع باز برای داده کاوی و یادگیری ماشین است. رابط بصری آن به شما این امکان را میدهد که گردشهای کاری علم داده سرتاسر، از مدلسازی تا تولید را ایجاد کنید. و اجزای مختلف از پیش ساخته شده، مدل سازی سریع را بدون وارد کردن یک خط کد امکان پذیر می کنند.
مجموعه ای از افزونه ها و ادغام های قدرتمند KNIME را به یک پلت فرم همه کاره و مقیاس پذیر برای پردازش انواع پیچیده داده ها و استفاده از الگوریتم های پیشرفته تبدیل می کند.
با KNIME، دانشمندان داده می توانند برنامه ها و خدماتی را برای تجزیه و تحلیل یا هوش تجاری ایجاد کنند. به عنوان مثال، در صنعت مالی، موارد استفاده رایج شامل امتیازدهی اعتبار، کشف تقلب و ارزیابی ریسک اعتباری است.

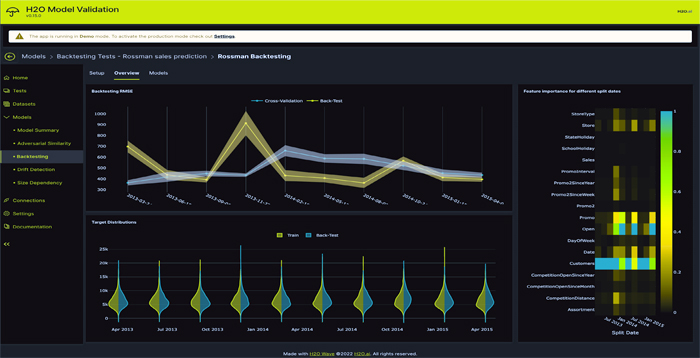
7- H2O
H2O یک پلت فرم یادگیری ماشین منبع باز است که هدف آن دسترسی به فناوری هوش مصنوعی برای همه است. از متداولترین الگوریتمهای ML پشتیبانی میکند و عملکردهای خودکار ML را ارائه میکند تا به کاربران کمک کند تا مدلهای یادگیری ماشینی را به روشی سریع و ساده بسازند، حتی اگر متخصص نباشند.
H2O را می توان از طریق یک API که در همه زبان های برنامه نویسی اصلی موجود است، ادغام کرد و از محاسبات در حافظه توزیع شده استفاده می کند، که آن را در هنگام تجزیه و تحلیل مجموعه داده های عظیم ایده آل می کند.
←برای خرید لایسنس Tableau با تمام ویژگی ها کلیک کنید
8- Orange
Orange یک جعبه ابزار علوم داده منبع باز رایگان برای توسعه، آزمایش و تجسم گردش کار داده کاوی است.
این یک نرم افزار مبتنی بر کامپوننت است که دارای مجموعه بزرگی از الگوریتم های یادگیری ماشینی از پیش ساخته شده و افزونه های متن کاوی است. همچنین دارای عملکردهای گسترده ای برای بیوانفورماتیکان و زیست شناسان مولکولی است.
Orange همچنین امکان تجسم دادههای تعاملی را فراهم میکند و گرافیکهای متعددی مانند نمودارهای سیلوئت و نمودارهای غربال را ارائه میدهد و غیربرنامهنویسان میتوانند وظایف داده کاوی را از طریق برنامهنویسی بصری در رابط کشیدن و رها کردن انجام دهند. در همین حال، توسعه دهندگان می توانند داده ها را در پایتون استخراج کنند.
9- Apache Mahout
Apache Mahout یک پلت فرم منبع باز برای ایجاد برنامه های کاربردی مقیاس پذیر با یادگیری ماشین است. هدف آن کمک به دانشمندان داده یا محققین در پیاده سازی الگوریتم های خود است.
این چارچوب که در جاوا اسکریپت نوشته شده و در بالای Apache Hadoop پیاده سازی شده است، بر سه حوزه اصلی تمرکز دارد: موتورهای توصیه گر، خوشه بندی و طبقه بندی. این برای پروژه های داده کاوی در مقیاس بزرگ و پیچیده که شامل حجم عظیمی از داده است، مناسب است. در واقع، توسط برخی از شرکت های وب پیشرو مانند لینکدین یا یاهو استفاده می شود.
Apache Mahout تحت مجوز Apache برای استفاده رایگان است و توسط جامعه بزرگی از کاربران پشتیبانی می شود.

10- SAS Enterprise Miner
SAS Enterprise Miner یک پلتفرم تجزیه و تحلیل و مدیریت داده است. هدف آن ساده کردن فرآیند داده کاوی است تا به متخصصان تحلیلگر کمک کند تا حجم زیادی از داده ها را به بینش تبدیل کنند.
از طریق یک رابط کاربری گرافیکی تعاملی (GUI)، کاربران می توانند مدل های داده کاوی را به سرعت تولید کنند و از آنها برای حل مسائل مهم تجاری استفاده کنند. SAS مجموعه ای غنی از الگوریتم ها را برای تهیه و کاوش داده ها و برای ساخت مدل های پیش بینی و توصیفی پیشرفته ارائه می دهد.
شرکتها میتوانند از SAS Enterprise Mining برای کشف تقلب، برنامهریزی منابع، و افزایش نرخ پاسخ در کمپینهای بازاریابی، از جمله برنامههای کاربردی دیگر استفاده کنند.
←برای خرید لایسنس Tableau با تمام ویژگی ها کلیک کنید
مقاله های مرتبط:
1- تفاوت و مقایسه هوش تجاری (BI) و انبار داده
2-توسعه پایگاه داده استاندارد SQL Server
3-چرا Data Structures یا ساختارهای داده مهم هستند؟
4-چرا Data Structures یا ساختارهای داده مهم هستند؟
5-تفاوت های داده های طبقه بندی شده (Categorical Data) در مقابل داده های عددی (Numerical Data)
6-تفاوت های داده های طبقه بندی شده (Categorical Data) در مقابل داده های عددی (Numerical Data)
8-داده های طبقه بندی شده (Categorical Data) چیست و چه ویژگی هایی دارد
9-چالش ها و نحوه مدیریت داده های همه جا حاضر یا Ubiquitous Data
10-معرفی انواع مدل های داده ای یا Data Model
11-Tableau در مقابل RapidMiner – مقایسه کنید و تفاوت آنها را درک کنید
12-ردیابی داده ها یا Data Tracking چیست و چه فایده ای دارد؟
13-توضیح و تفاوت های داده های سخت (Hard Data) در مقابل داده های نرم (Soft Data)