
Decision Tree (درخت تصمیم) چیست؟ راهنمای جامع برای درک یکی از قدرتمندترین الگوریتمهای یادگیری ماشین
در دنیای یادگیری ماشین و علم داده، الگوریتمهای متعددی برای حل مسائل پیچیده وجود دارند. در میان آنها، Decision Tree (درخت تصمیم) به دلیل سادگی، قابلیت تفسیر بالا و قدرت تحلیلی خود، جایگاه ویژهای دارد. اما دقیقاً Decision Tree چیست و چگونه به ما کمک میکند تا از دل دادهها، بینشهای قابل فهمی را استخراج کنیم؟
این مقاله به طور جامع به بررسی مفهوم Decision Tree، نحوه عملکرد، انواع، مزایا، معایب و کاربردهای آن میپردازد و نشان میدهد که چرا این الگوریتم، حتی با وجود توسعه روشهای پیچیدهتر، همچنان یک ابزار بنیادین و پرکاربرد در جعبه ابزار هر دانشمند داده محسوب میشود.
Decision Tree چیست؟ ساختار یک درخت تصمیم
Decision Tree (درخت تصمیم) یک الگوریتم یادگیری ماشین نظارتشده (Supervised Learning) است که هم برای مسائل طبقهبندی (Classification) و هم برای مسائل رگرسیون (Regression) قابل استفاده است. ساختار آن شبیه به یک فلوچارت (Flowchart) یا یک درخت واقعی است که از “نودها” (Nodes) و “شاخهها” (Branches) تشکیل شده است. هدف اصلی درخت تصمیم این است که با تقسیمبندی مکرر دادهها بر اساس مجموعهای از قوانین تصمیمگیری، به یک نتیجهگیری یا پیشبینی نهایی برسد.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
اجزای اصلی یک Decision Tree عبارتند از:
- Root Node (نود ریشه): این نود اولیه در بالای درخت قرار دارد و نشاندهنده کل مجموعه داده است که شروع فرآیند تصمیمگیری از آنجا آغاز میشود.
- Internal Nodes (نودهای داخلی/تصمیم): این نودها نشاندهنده یک “تست” یا “سوال” بر روی یکی از ویژگیهای (Features) داده هستند (مثلاً “آیا سن مشتری > 30 است؟”). هر نود داخلی دارای دو یا چند شاخه است که نتیجه آن تست را نشان میدهند.
- Branches (شاخهها): هر شاخه، نتیجه یک تصمیم (پاسخ به سوال در نود) را نشان میدهد و به نود بعدی هدایت میکند.
- Leaf Nodes (نودهای برگ/پایانی): این نودها در انتهای درخت قرار دارند و نشاندهنده نتیجه نهایی پیشبینی یا طبقهبندی هستند. به عبارت دیگر، وقتی به یک نود برگ میرسید، درختهای تصمیم به پیشبینی نهایی خود دست یافته است.
تصویر 1: ساختار ساده یک Decision Tree شامل نود ریشه، نودهای داخلی (تصمیم)، شاخهها و نودهای برگ (پیشبینی نهایی)
درخت تصمیم چگونه کار میکند؟ فرآیند تقسیمبندی
فرآیند ساخت یک Decision Tree، که به آن “یادگیری” یا “رشد” درخت نیز گفته میشود، شامل تقسیمبندی مکرر مجموعه داده است. این فرآیند به صورت بازگشتی انجام میشود:
-
انتخاب بهترین ویژگی برای تقسیمبندی: در هر نود (شروع از نود ریشه)، الگوریتم تمام ویژگیهای موجود را بررسی میکند تا بهترین ویژگی را برای تقسیمبندی دادهها انتخاب کند. معیار انتخاب بهترین ویژگی، “کاهش ناخالصی” (Impurity Reduction) است. دو معیار رایج برای اندازهگیری ناخالصی عبارتند از:
- Gini Impurity (ناخالصی جینی): احتمال دستهبندی اشتباه یک عنصر انتخاب شده تصادفی از مجموعه. هدف درخت، حداقل کردن این مقدار است.
- Entropy (آنتروپی/افزایش اطلاعات): اندازهگیری میزان بینظمی یا عدم قطعیت در یک مجموعه داده. هدف، بیشینه کردن “Information Gain” (کاهش آنتروپی) است.
-
تقسیمبندی نود: پس از انتخاب بهترین ویژگی، نود بر اساس آستانه (Threshold) یا دستهبندیهای آن ویژگی، به زیرمجموعههایی تقسیم میشود. این زیرمجموعهها به شاخههای جدیدی تبدیل شده و نودهای فرزند را تشکیل میدهند.
-
تکرار فرآیند: این مراحل برای هر نود فرزند به صورت بازگشتی تکرار میشوند تا زمانی که یکی از معیارهای توقف (Stopping Criteria) برآورده شود.
معیارهای توقف (Stopping Criteria):
- حداکثر عمق درخت (Max Depth): درخت از عمق مشخصی فراتر نرود.
- حداقل تعداد نمونهها در یک برگ (Min Samples per Leaf): یک نود برگ حداقل تعداد مشخصی از نمونهها را داشته باشد.
- حداقل تعداد نمونهها برای تقسیم نود (Min Samples Split): یک نود برای تقسیم شدن، حداقل تعداد مشخصی از نمونهها را داشته باشد.
- ناخالصی نود (Node Impurity): اگر ناخالصی یک نود زیر یک آستانه مشخص باشد، نیازی به تقسیم بیشتر نیست.
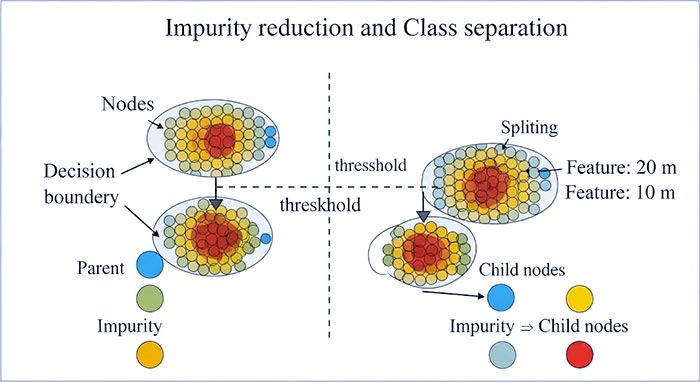
تصویر 2: نمایش بصری فرآیند تقسیمبندی (Splitting) در یک درخت تصمیم که هدف آن کاهش ناخالصی و جداسازی کلاسها است.
انواع درخت تصمیم
Decision Tree ها بر اساس نوع متغیر هدف، به دو دسته اصلی تقسیم میشوند:
-
Classification Trees (درختان طبقهبندی): برای پیشبینی یک متغیر هدف گسسته (Categorical) استفاده میشوند. به عنوان مثال، پیشبینی اینکه آیا یک مشتری “خریدار” خواهد بود یا “خیر”، یا اینکه ایمیلی “هرزنامه” است یا “عادی”. نودهای برگ در این نوع درختان، یک برچسب کلاس (Class Label) را نمایش میدهند.
-
Regression Trees (درختان رگرسیون): برای پیشبینی یک متغیر هدف پیوسته (Continuous) استفاده میشوند. به عنوان مثال، پیشبینی قیمت خانه، میزان دما یا حجم فروش. نودهای برگ در این نوع درختان، یک مقدار عددی (مانند میانگین مقادیر نمونههای موجود در آن برگ) را نمایش میدهند.
مزایای Decision Tree (درخت تصمیم)
درخت تصمیم به دلیل ویژگیهای منحصربهفرد خود، الگوریتمی بسیار محبوب است:
- قابلیت تفسیر و توضیحپذیری بالا (Interpretability/Explainability): مهمترین مزیت آنهاست. ساختار فلوچارتمانند آنها باعث میشود که قوانین تصمیمگیری به راحتی توسط انسان قابل فهم باشند، حتی برای افرادی که دانش فنی عمیقی در یادگیری ماشین ندارند.
- پشتیبانی از انواع داده: میتواند هم با دادههای عددی (Numerical) و هم با دادههای دستهای (Categorical) کار کند.
- نیاز کمتر به پیشپردازش دادهها: بر خلاف بسیاری از الگوریتمها، Decision Tree ها نیازی به نرمالسازی (Normalization) یا مقیاسبندی (Scaling) ویژگیها ندارند.
- قابلیت مدلسازی روابط غیرخطی: میتوانند روابط پیچیده و غیرخطی بین ویژگیها و متغیر هدف را کشف کنند.
- نسبتاً مقاوم در برابر دادههای پرت (Outliers): کمتر تحت تأثیر دادههای پرت قرار میگیرند.
معایب و چالشهای درخت تصمیم
با وجود مزایای فراوان، درخت تصمیم دارای چالشهایی نیز هست:
- بیشبرازش (Overfitting): این بزرگترین نقطه ضعف درخت تصمیم است. درختان به سادگی میتوانند بیش از حد پیچیده شوند و جزئیات نویز موجود در دادههای آموزشی را نیز یاد بگیرند، که منجر به عملکرد ضعیف روی دادههای جدید و ندیده شده میشود.
- ناپایداری (Instability): تغییرات کوچک در دادههای ورودی میتواند منجر به ایجاد یک ساختار درختی کاملاً متفاوت شود.
- سوگیری (Bias) در برابر کلاسهای غالب: در مجموعهدادههای نامتوازن (Imbalanced Datasets)، درخت تصمیم ممکن است به سمت کلاسهای پرتعدادتر سوگیری پیدا کند.
- بهینه نبودن برای متغیرهای پیوسته با مقادیر متمایز زیاد: برای ویژگیهای پیوسته که دارای مقادیر منحصر به فرد زیادی هستند، ممکن است درختان بسیار بزرگ و پیچیده شوند.
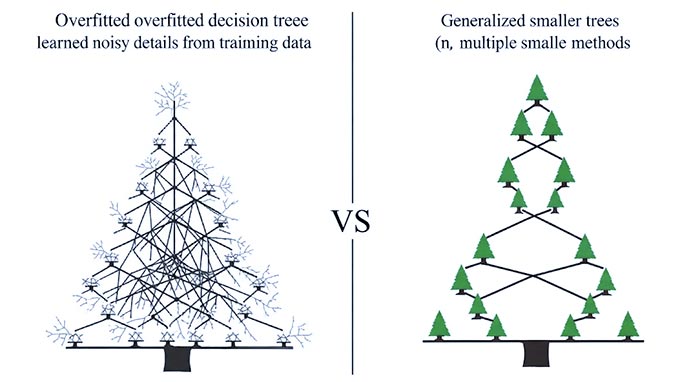
تصویر 3: مقایسه بصری یک درخت تصمیم بیشبرازشیافته (چپ) که جزئیات نویز را یاد گرفته، با یک درخت سادهتر و تعمیمیافته (راست) یا مفهوم چندین درخت کوچکتر در روشهای جمعی.
غلبه بر چالشها: هرس کردن (Pruning) و روشهای جمعی (Ensemble Methods)
برای کاهش مشکل بیشبرازش و بهبود پایداری درخت تصمیم، از دو تکنیک اصلی استفاده میشود:
-
هرس کردن (Pruning):
- Pre-pruning (هرس پیشین): درخت را قبل از اینکه به طور کامل رشد کند، متوقف میکند. این کار با اعمال معیارهای توقف سختگیرانهتر (مثلاً حداکثر عمق کمتر یا حداقل نمونههای بیشتر در برگ) انجام میشود.
- Post-pruning (هرس پسین): درخت را به طور کامل رشد میدهد و سپس شاخهها و نودهایی را که کمک چندانی به دقت نمیکنند یا باعث بیشبرازش میشوند، حذف میکند.
-
روشهای جمعی (Ensemble Methods): این روشها قدرت درخت تصمیم را چندین برابر میکنند. ایده اصلی این است که به جای استفاده از یک درخت تصمیم منفرد، چندین درخت تصمیم ساخته و پیشبینیهای آنها ترکیب شود تا نتیجه نهایی قویتر و پایدارتر باشد:
- Random Forests (جنگلهای تصادفی): تعداد زیادی درخت تصمیم مستقل ساخته میشوند که هر یک روی زیرمجموعهای تصادفی از دادهها و ویژگیها آموزش دیدهاند. سپس پیشبینیهای آنها با رأیگیری (برای طبقهبندی) یا میانگینگیری (برای رگرسیون) ترکیب میشوند.
- Gradient Boosting (تقویت گرادیان) (مثلاً XGBoost, LightGBM): در این روش، درختان به صورت متوالی ساخته میشوند، به گونهای که هر درخت تصمیم جدید تلاش میکند خطاهای پیشبینیشده توسط درختان قبلی را اصلاح کند. این روشها اغلب به بالاترین دقت در بسیاری از مسائل دست مییابند.
این روشهای جمعی، قدرت Decision Tree را حفظ کرده و در عین حال نقاط ضعف آن را به میزان قابل توجهی کاهش میدهند، به همین دلیل در بسیاری از مسائل دنیای واقعی به شدت محبوب و موفق هستند.
کاربردهای درخت تصمیم در عمل
درختتصمیم ها به دلیل سادگی و قابلیت تفسیر، در حوزههای مختلفی کاربرد دارند:
- پیشبینی ریزش مشتری (Customer Churn Prediction): شناسایی مشتریانی که در معرض ترک سرویس هستند.
- تشخیص پزشکی (Medical Diagnosis): کمک به تشخیص بیماریها بر اساس علائم.
- ارزیابی ریسک اعتباری (Credit Risk Assessment): تعیین اعتبار مشتریان برای دریافت وام.
- تشخیص تقلب (Fraud Detection): شناسایی تراکنشهای مشکوک.
- بازاریابی هدفمند (Target Marketing): تقسیمبندی مشتریان برای کمپینهای بازاریابی مؤثرتر.
نتیجهگیری
Decision Tree (درختتصمیم) یک الگوریتم قدرتمند و شهودی در حوزه یادگیری ماشین است که با ساختار درختی و قوانین تصمیمگیری واضح خود، بینشهای قابل تفسیر و قابل اجرا را از دادهها استخراج میکند. با وجود چالشهایی مانند بیشبرازش و ناپایداری، تکنیکهای پیشرفتهای مانند هرس کردن و به خصوص روشهای جمعی (مانند Random Forests و Gradient Boosting) توانستهاند این نقاط ضعف را به خوبی پوشش دهند و درختتصمیم را به یکی از ابزارهای ضروری و پرکاربرد در تحلیل داده و هوش مصنوعی تبدیل کنند. درک این الگوریتم، گام مهمی برای هر کسی است که میخواهد به دنیای وسیع یادگیری ماشین قدم بگذارد.
مقاله های مرتبط:
1- چگونه بر چالش های تبدیل شدن به یک تحلیلگر داده غلبه کنیم؟
2- 12 تا از بهترین ابزار و نرم افزارهای آماده سازی داده ها
3- ویژگی های برتر Tableau نرم افزار برای داشبوردسازی
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها