

آشنایی با استاندارد داده های مرتب (Tidy Data)
در زمینه تحقیق توسعه، دادههای نظرسنجی به ندرت در قالب منظم به دست میآیند. یک متغیر مجموعه ای از نقاط داده است که ویژگی یکسانی را در واحدها اندازه گیری می کند، یعنی نام، سن، درآمد و غیره. یک متغیر یک ستون واحد را تشکیل می دهد. مشاهده مجموعه ای از مقادیر است که بر روی یک واحد در بین ویژگی ها اندازه گیری می شود. به عنوان مثال، در بررسی الگوهای کشت فصلی برای 1000 خانوار در یک منطقه، هر خانوار یک مشاهده است. هر مشاهده به چند ردیف جدا می شود.
هر نقطه داده نشان دهنده یک متغیر و یک مشاهده است. مجموعه داده مجموعه ای از نقاط داده است و رایج ترین شکلی که در آن سازماندهی می شود جدول داده است. کار با همه جداول داده آسان نیست، اما کار در مدیریت پایگاه داده نشان داده است که ساده ترین فرمت برای کار با آنها
#داده های مرتب (Tidy Data)
مجموعه داده های آشفته
این بخش سه مشکل رایج در مجموعه دادههای نامرتب را به همراه راهحلهای آنها شرح میدهد:
- سرصفحه های ستون مقادیر هستند، نه نام متغیرها
- چندین متغیر در یک ستون ذخیره می شوند
- متغیرها در هر دو سطر و ستون ذخیره می شوند
۱- سرصفحه های ستون مقادیر هستند، نه نام متغیرها
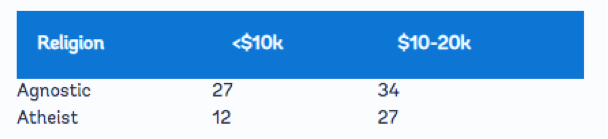
مجموعه داده برش خورده زیر را در نظر بگیرید که رابطه بین درآمد و مذهب را با سه متغیر «درآمد»، «مذهب» و «تکرار» بررسی میکند. توجه داشته باشید که مقادیر متغیر “درآمد” در واقع ستون های مجموعه داده ما هستند:
سرصفحه های ستون به عنوان نام متغیر
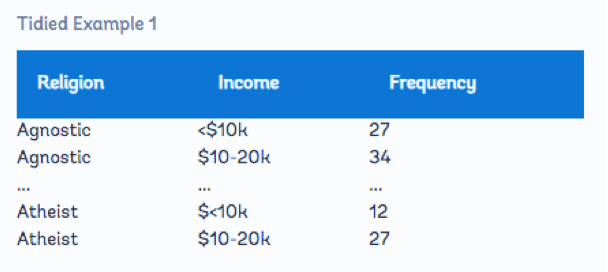
مجموعه داده مرتب شده به صورت زیر است:
۲- چندین متغیر در یک ستون ذخیره می شوند
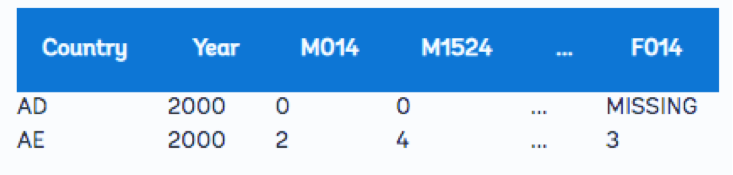
مشکل دیگر داده زمانی است که چند بیت از اطلاعات در یک سلول رمزگذاری می شوند. نگاهی به مجموعه داده سل برش داده شده در زیر بیندازید. مربوط به هر ستون “M” برای مردان، همچنین یک ستون “F” برای زنان وجود دارد. ستون های میانی بین M1524 و F014 که مردان 24 تا 65 ساله را نشان می دهند برای صرفه جویی در فضا نشان داده نمی شوند:
چند متغیر ذخیره شده در یک ستون
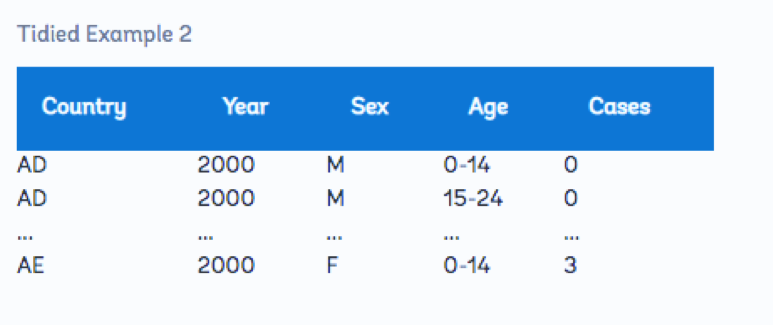
در این بخش نحوه اصلاح مشکل توضیح داده نمی شود، اما جدول زیر داده های مرتب شده را نشان می دهد که در آن دو ستون وجود دارد، یکی برای متغیر سن و دیگری برای متغیر جنسیت:
۳- متغیرها در هر دو سطر و ستون ذخیره می شوند
به مجموعه داده آب و هوای زیر نگاهی بیندازید. توجه داشته باشید که عجیب به نظر می رسد: اطلاعات آب و هوا معمولاً در سطح “روز” گزارش می شود. یعنی هر مشاهده یک روز است و ما باید برای هر روز یک مقدار حداکثر و حداقل دما داشته باشیم. با این حال، در قالب مجموعه داده اولیه “طولانی”، می بینیم که داده ها با مقادیر تاریخ و عناصر به جای آن ذخیره می شوند:
متغیرها در هر دو سطر و ستون ذخیره می شوند
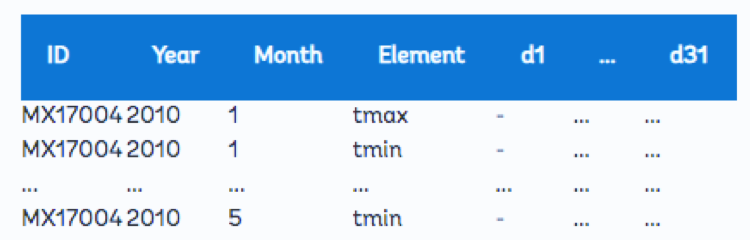
توجه داشته باشید که روزهای 2-30 برای صرفه جویی در فضا حذف شده است. همچنین توجه داشته باشید که این مجموعه داده خاص برش داده شده است و به نظر می رسد بسیاری از مقادیر در جدول بالا گم شده اند. مجموعه داده مرتب شده زیر برخی از مقادیر از دست رفته را نشان می دهد. باز هم، این بخش نحوه مرتب سازی داده ها را نشان نمی دهد، فقط نتیجه خود مرتب سازی است:
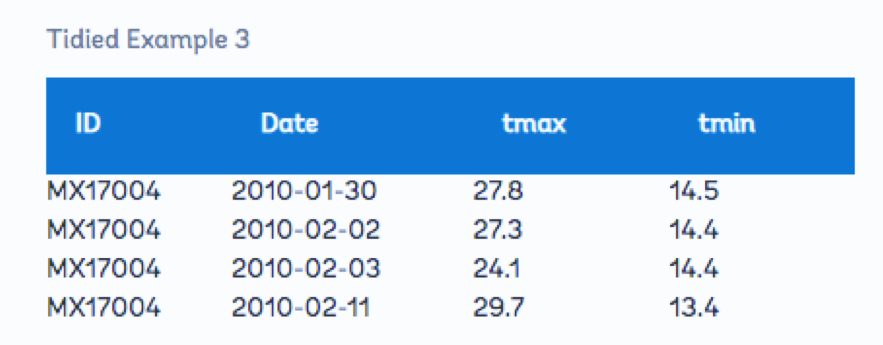
برای مطالعه بیشتر در مورد مرتب کردن دادهها، مانند مراحل مرتب کردن دادهها در مثالهای 2 و 3 بالا و همچنین مجموعه دادههای کامل هر نمونه که ممکن است زمینه بیشتری را فراهم کند، کتابی از دانیل چن و آن را بررسی کنید Science Data for the Biomedical Sciences. براون، و این مقاله در مورد مرتب کردن داده ها. آنها همچنین در بخش منابع اضافی پیوند داده شده اند.
مورد ساده: تغییر شکل
وقتی همه مشاهدات در یک جدول داده دارای واحد مشاهده یکسانی هستند، تغییر شکل برای مرتب کردن داده های نامرتب کافی است. تغییر شکل عبارت است از تبدیل سازماندهی سطرها و ستون ها در یک جدول داده به گونه ای که واحد مشاهده نشان داده شده توسط یک ردیف تغییر کند. این را می توان در Stata با استفاده از دستور reshape انجام داد. توجه به این نکته ضروری است که تغییر شکل محتوای نقاط داده در جدول را تغییر نمی دهد.
بیایید نگاهی به مثال زیر بیندازیم که از کتاب الکترونیکی A Modern Dive into R and the Tidyverse گرفته شده است. به جدول زیر نگاه کنید.
قیمت سهام: فرمت غیر مرتب

توجه داشته باشید که در اینجا سه متغیر وجود دارد:
- تاریخ
- نام سهام
- قیمت سهام
در حالی که داده ها به طور منظم در قالب صفحه گسترده سازماندهی شده اند، اما در قالب مرتب نیستند زیرا سه ستون مربوط به سه متغیر وجود ندارد. به یاد داشته باشید، در یک قالب مرتب، هر متغیر باید ستون خودش باشد. جدول زیر سازماندهی مجدد داده ها را در این قالب مرتب نشان می دهد.
قیمت سهام: فرمت مرتب

توجه داشته باشید که هر متغیر (تاریخ، قیمت سهام و قیمت سهام) ستون مخصوص به خود را دارد. فرمت داده های غیر مرتب در جدول اصلی به عنوان فرمت گسترده نیز شناخته می شود در حالی که قالب داده مرتب در جدول دوم به عنوان فرمت داده طولانی / باریک نیز شناخته می شود.
موارد پیچیده تر
یک مشکل پیچیده تر که اغلب با آن مواجه می شود این است که یک مجموعه داده از چندین واحد مشاهده تشکیل شده است که در یک جدول ذخیره می شوند. این مشکل در سه مرحله حل می شود:
- همه متغیرهایی که در همان سطح مشاهده اندازه گیری شده اند را شناسایی کنید
- برای هر سطح مشاهده جداول جداگانه ایجاد کنید
- داده ها را تغییر شکل دهید
در پایان این فرآیند، مجموعه داده شما از چندین جدول داده تشکیل شده است، یک جدول برای هر واحد مشاهده. برای ارائه یک مثال ملموس، فرض کنید که ما یک جدول داده داریم که از دو متغیر سن و جنسیت تشکیل شده است، که در آن متغیرهای جدول دارای دو واحد مشاهده متفاوت هستند: خانواده و عضو خانواده. از آنجایی که سن و جنسیت در دو سطح مختلف اندازهگیری میشوند، به دو ستون تقسیم میشوند و هر ردیف شامل چندین مشاهدات است.
دو مؤلفه اضافی وجود دارد که برای مدیریت موفقیت آمیز مجموعه ای از جداول مرتب بسیار مهم است:
- هر جدول باید منحصراً و به طور کامل توسط یک یا مجموعه ای از متغیرهای ID شناسایی شود
- شما باید بتوانید از این متغیرهای ID برای پیوند دادن همه جداول داده به یکدیگر استفاده کنید
با افزایش تعداد گروههای تودرتو، فرآیند مرتب کردن پیچیدهتر میشود: مراحل شناسایی واحد مشاهده هر متغیر و تغییر شکل جداول جدا شده باید تکرار شوند. با این حال، هرچه گروههای تودرتو بیشتر یک مجموعه داده را شامل شود، در مقایسه با دادههای نامرتب، کارآمدتر است.
بیایید مثال خانگی ذکر شده در بالا را تجسم کنیم. جدول زیر را در نظر بگیرید:
میز غیر مرتب

این داده ها مرتب نیستند. ابتدا توجه داشته باشید که متغیرها دارای دو واحد مشاهده متفاوت هستند: خانواده و عضو خانواده. در نتیجه، ما چندین ستون برای یک متغیر داریم: دو ستون برای جنسیت و دو ستون برای سن. دوم، توجه داشته باشید که هر ردیف شامل چندین مشاهدات است.
چگونه این داده ها را مرتب کنیم؟ ما باید دو جدول جداگانه بسازیم، یکی برای هر واحد مشاهده و سپس آن را تغییر شکل دهیم.
میز مرتب: سطح خانگی
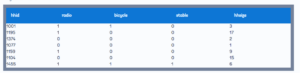
جدول مرتب: سطح اعضای خانواده

توجه داشته باشید که اکنون دو جدول مربوط به دو واحد مشاهده است، جدول اول در سطح خانوار و جدول دوم در سطح اعضای خانوار. اکنون هر کدام یک ستون برای متغیرهای جنسیت و سن وجود دارد و هر ردیف شامل یک مشاهده است.
ارتباط برای پاکسازی داده ها
هنگام تمیز کردن دادهها و بهویژه دادههای بررسی، معمولاً لازم است مقادیر را مجدداً کدگذاری کنید، متغیرها و مقادیر را برچسبگذاری کنید و متغیرها را بررسی کنید. تمیز کردن داده های مرتب آسان تر است زیرا در مجموعه داده مرتب، هر متغیر با یک سوال نظرسنجی مطابقت دارد:
- هر سوال دارای مجموعه ای از گزینه های یکسان است، می توانید آنها را به جای حلقه زدن بر روی چندین ستون، روی یک ستون در یک مجموعه داده مرتب اعمال کنید.
- با استفاده از یک مجموعه داده مرتب، می توانید تمام پاسخ های یک سوال را به راحتی خلاصه کنید
مقاله های مرتبط:
1- معرفی انواع مدل های داده ای یا Data Model
2- داده های عددی (Numerical Data) چیست و چه ویژگی هایی دارد
3- چگونه می توان داده ها را به اطلاعات تبدیل کرد؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها
#داده های مرتب (Tidy Data)