

یادگیری علم داده با پایتون (Python)
پایتون معمولاً انتخاب همه برای یک زبان برنامه نویسی در صنعت علم داده است و در سال های اخیر به تدریج محبوبیت پیدا کرده است. در سال 2017، طبق نظرسنجی انجام شده توسط KDNuggets، پایتون از نظر محبوبیت جایگزین R شد، و مشابه آن برای سال 2018 بود. و اخیراً، پایتون به عنوان محبوب ترین زبان برنامه نویسی بر اساس شاخص TIOBE در سال 2021 ظاهر شده است.
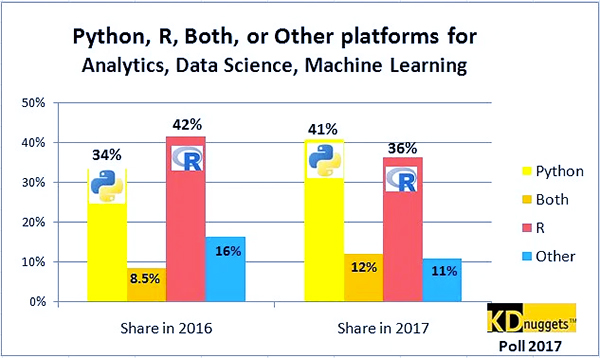
پایتون معمولاً انتخاب همه برای یک زبان برنامه نویسی در صنعت علم داده است و در سال های اخیر به تدریج محبوبیت پیدا کرده است
مبتدیان در علم داده اغلب می پرسند، آیا پایتون برای علم داده لازم است؟ پاسخ خیر است، Python برای یادگیری علم داده ضروری نیست، اما اگر آن را یاد بگیرید، مفید خواهد بود.
- پایتون نوشتن کدها را آسان می کند.
- Python یک زبان آسان برای خواندن است.
- رایگان و متن باز است.
- این یک زبان برنامه نویسی شی گرا است.
- این یکی از بهترین زبان ها برای تکمیل کارهای تجسم داده و پاکسازی داده ها است.
- این شامل کتابخانه هایی مانند NumPy، Pandas و غیره است که به راحتی داده های بزرگ را مدیریت می کنند.
- این توسط جامعه بزرگی از توسعه دهندگان از سراسر جهان پشتیبانی می شود.
چگونه اصول پایتون را برای علم داده یاد بگیریم؟
در این بخش، اصول اولیه پایتون را که برای یادگیری علم داده با پایتون ضروری است، مورد بحث قرار خواهیم داد.
اصول پایتون برای علم داده
قبل از کاوش در کتابخانههایی که به پیادهسازی الگوریتمهای علم داده کمک میکنند، یادگیری اصول پایتون بسیار مهم است. بنابراین، نحوه نوشتن دستورات ساده در پایتون و پیاده سازی حلقه های مختلف در پایتون را بیاموزید. بر روی لیست کلمات کلیدی رزرو شده توسط پایتون تمرکز کنید و انواع داده های زبان (آرایه، لیست، تاپل، دیکشنری، مجموعه ها و غیره) را بررسی کنید.
پس از یادگیری اصول اولیه، سعی کنید برنامه های نمونه برای مشکلات زیر ایجاد کنید:
بررسی کنید که آیا یک عدد ورودی اول است یا خیر.
HCF و LCM دو عدد ورودی را چاپ کنید.
الگوی زیر را با استفاده از حلقه for چاپ کنید:
*
**
***
**
*
کتابخانه های پایتون برای علم داده
پایتون کتابخانه های زیادی دارد که از پیاده سازی الگوریتم های مختلف در علم داده پشتیبانی می کند. در زیر تعدادی از این کتابخانه ها آورده شده است.

1- Scikit-learn
این کتابخانه شامل تمام کدهای پیاده سازی الگوریتم های یادگیری ماشین مانند رگرسیون خطی، رگرسیون لجستیک و غیره است. دانشمندان داده از این کتابخانه برای پیاده سازی الگوریتم های ML و ارزیابی کیفیت برازش مدل استفاده می کنند. همچنین میتوان از Scikit-learn برای پیادهسازی تکنیک اعتبارسنجی متقابل بر روی مجموعه دادههای داده شده استفاده کرد. همچنین شامل چند مجموعه داده نمونه است که می توان از آنها برای درک اجرای الگوریتم های مختلف استفاده کرد.
2- Pandas
این کتابخانه شامل توابع مختلفی است که می توان از آنها برای خواندن، نوشتن و تجزیه و تحلیل فایل csv. استفاده کرد. همچنین ساختار داده سری را ارائه می دهد که دانشمندان داده می توانند از آن برای مدیریت داده های یک بعدی استفاده کنند. بخش هیجان انگیز استفاده از این کتابخانه این است که امکان تبدیل انواع داده ها مانند لیست، تاپل یا دیکشنری به ساختار سری را فراهم می کند. با Pandas ، میتوانید دادههای خود را به یک DataFrame تبدیل کنید و از روشهای مختلف از پیش تعریفشده برای دریافت یک نمای کلی از آن دادهها استفاده کنید.
3- NumPy
این کتابخانه شامل روش های مختلفی برای محاسبه علمی آرایه های n بعدی است. می توان با کمک NumPy آرایه ها را ایجاد، دستکاری و فهرست کرد و علاوه بر این، روش های لازم برای پخش آرایه ها را فراهم می کند.
4- Matplotlib
این یک کتابخانه تجسم داده است و به رسم نمودارها و نمودارهای مختلف کمک می کند. این به کاربران اجازه می دهد تا نمودارهای میله ای، نمودار دایره ای، هیستوگرام و غیره از نظر بصری جذاب ایجاد کنند.
5- Seaborn
Seaborn یکی دیگر از کتابخانه های تجسم داده است که به کاربران اجازه می دهد انواع مختلف نمودارها را رسم کنند. Seaborn نمودارهای جذاب بصری بهتری نسبت به matplotlib ارائه می دهد.
6- Keras
این کتابخانه از اجرای روان الگوریتم های پیچیده مانند شبکه های عصبی پشتیبانی می کند. این به کاربران اجازه می دهد تا لایه های بیشتری را به شبکه اضافه کنند و بنابراین قابل گسترش است. دانشمندان داده از Keras با چارچوب هایی مانند Tensor و Thenao برای ساخت مدل های قدرتمندتر استفاده می کنند.
←برای خرید کرک Tableau با تمام ویژگی ها کلیک کنید
مقاله های مرتبط:
1-تکنیک های مدل سازی در تحلیل کسب و کار با R
2-بهترین ابزارهای ETL در سال 2024