

کدام پایگاه داده برای یادگیری ماشینی بهتر است؟
انتخاب بهترین پایگاه داده برای یادگیری ماشین به عوامل مختلفی مانند ماهیت دادههای شما، مقیاس پروژه، الزامات خاص الگوریتمهای یادگیری ماشین و زیرساخت کلی شما بستگی دارد. در اینجا چند پایگاه داده که معمولاً در پروژه های یادگیری ماشین استفاده می شود آورده شده است:
1- پایگاه های داده رابطه ای (RDBMS):
پایگاه دادههای رابطهای مانند PostgreSQL و MySQL برای پروژههای یادگیری ماشینی که در آن دادههای ساختاریافته درگیر هستند، مناسب هستند. آنها انطباق با ACID، سازگاری قوی و قابلیتهای جستجوی SQL را ارائه میدهند. پایگاههای داده رابطهای اغلب برای ذخیره ابردادهها، برچسبها و سایر دادههای ساختاریافته مرتبط با یادگیری ماشین استفاده میشوند. وظایف
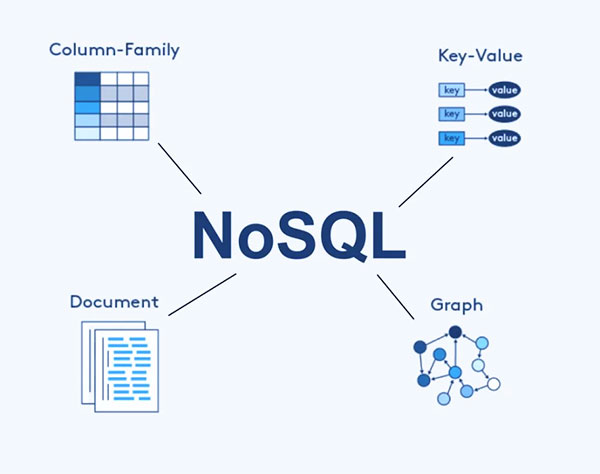
2- پایگاه های داده NoSQL:
پایگاههای داده NoSQL برای مدیریت حجم زیادی از دادههای بدون ساختار یا نیمه ساختار یافته که معمولاً در برنامههای یادگیری ماشین با آنها مواجه میشوند، محبوب هستند. پایگاههای داده سندگرا مانند MongoDB برای ذخیرهسازی اسناد JSON-مانند مناسب هستند و آنها را به انتخاب خوبی برای مدیریت طرحوارههای انعطافپذیر تبدیل میکند. ارزش کلیدی فروشگاههایی مانند Redis میتوانند برای ذخیرهسازی موقت، ذخیرهسازی موقت و مدیریت نتایج میانی در خطوط لوله یادگیری ماشین مفید باشند. پایگاههای اطلاعاتی نمودار مانند Neo4j برای مدلسازی و تحلیل روابط پیچیده بین موجودیتهای داده، مانند شبکههای اجتماعی یا سیستمهای توصیه مناسب هستند.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
3- پایگاه های داده درون حافظه:
پایگاههای اطلاعاتی درون حافظه مانند Redis و Apache Ignite برای برنامههای یادگیری ماشینی که نیاز به دسترسی سریع خواندن و نوشتن به دادهها دارند، مفید هستند. آنها اغلب برای ذخیرهسازی دادههای با دسترسی مکرر، مدیریت وضعیتهای جلسه، و ذخیره نتایج میانی در طول آموزش مدل و استنتاج استفاده میشوند.
4- انبارهای داده:
انبارهای داده مانند Amazon Redshift، Google BigQuery و Snowflake برای ذخیره و تجزیه و تحلیل حجم زیادی از داده های ساختاریافته مناسب هستند. آنها قابلیت های پردازش موازی (MPP)، ذخیره سازی ستونی، و پشتیبانی از پرس و جوهای تحلیلی مبتنی بر SQL را ارائه می دهند. انبارهای داده معمولاً استفاده می شوند. برای اجرای تجزیه و تحلیل دسته ای، ایجاد ویژگی هایی برای مدل های یادگیری ماشینی و انجام تجزیه و تحلیل داده های موقت.
5- سیستم های فایل توزیع شده:
سیستمهای فایل توزیعشده مانند Hadoop Distributed File System (HDFS) و Amazon S3 برای ذخیره مجموعههای داده در مقیاس بزرگ به شیوهای توزیعشده مناسب هستند. آنها معمولاً در ارتباط با چارچوبهای پردازش دادههای بزرگ مانند Apache Spark و Apache Hadoop برای پیشپردازش دادهها، مهندسی ویژگیها استفاده میشوند. ، و آموزش مدل توزیع شده.
در نهایت، انتخاب پایگاه داده برای یادگیری ماشین به عواملی مانند حجم داده، ساختار داده، الگوهای دسترسی، الزامات عملکرد و ادغام با زیرساخت ها و ابزارهای موجود بستگی دارد. ضروری است که مبادلات هر نوع پایگاه داده را ارزیابی کنید و یکی را انتخاب کنید که به بهترین وجه متناسب با مورد خاص استفاده از یادگیری ماشین شما باشد.
مقاله های مرتبط:
1- توسعه پایگاه داده استاندارد SQL Server
2- کارشناس پایگاه داده کیست؟
3- چگونه یادگیری ماشینی می تواند در داده کاوی مفید باشد
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها