
منظور از دادههای جاسازیشده چیست؟
«دادههای جاسازیشده، دادهها و تجزیه و تحلیلهایی هستند که به طور یکپارچه با محتوا یا خدماتی که به کاربر نهایی ارائه میشود، ادغام شدهاند. این دادهها در هر جایی که کاربر میخواهد، روی هر دستگاهی که میخواهد، چه صفحه وب، نرمافزار یا موبایل، در دسترس هستند. این قابلیت، دسترسی به تجزیه و تحلیل دادهها بدون ترک تجربه کاربری است.»
جاسازی داده ها به نمایش نقاط داده، مانند متن، تصاویر یا صدا، به عنوان بردارهایی در یک فضای برداری پیوسته اشاره دارد. این امر به مدلهای یادگیری ماشین و الگوریتمهای جستجوی معنایی اجازه میدهد تا روابط بین نقاط داده را بر اساس نزدیکی آنها در فضای برداری درک کنند. اساساً، جاسازی داده های پیچیده را به قالبی عددی تبدیل میکنند که کامپیوترها میتوانند به راحتی آن را پردازش و تجزیه و تحلیل کنند.
1. هدف جاسازیها:
- فعال کردن یادگیری ماشین:
جاسازیها برای بسیاری از وظایف یادگیری ماشین، به ویژه آنهایی که شامل دادههای بدون ساختار مانند متن و تصاویر هستند، بسیار مهم هستند. - درک معنایی:
آنها معنا و روابط بین نقاط داده را ثبت میکنند و به مدلها اجازه میدهند شباهتها و تفاوتها را درک کنند. - کاهش ابعاد:
جاسازیها میتوانند دادههای با ابعاد بالا را در فضایی با ابعاد پایینتر نمایش دهند و کار با آنها و تجسم آنها را آسانتر کنند. - جستجوی کارآمد شباهت:
با نمایش دادهها به صورت بردار، میتوان از الگوریتمهای جستجوی کارآمد برای یافتن نقاط داده مشابه استفاده کرد.
۲. نحوه کار جاسازی داده ها:
- از دادههای خام تا بردارها:
جاسازیها با آموزش مدلهای یادگیری ماشین روی یک مجموعه داده بزرگ از نوع داده هدف ایجاد میشوند. - بازنمایی برداری:
مدل یاد میگیرد که هر نقطه داده را به یک بردار در یک فضای چند بعدی نگاشت کند. - شباهت فاصله است:
در فضای برداری، فاصله بین دو بردار نشاندهنده شباهت بین نقاط داده مربوطه است. بردارهای نزدیکتر به معنای دادههای مشابهتر هستند.
۳. انواع جاسازی داده ها:
- جاسازیهای کلمه:
کلمات را به صورت بردار نمایش میدهند و روابط معنایی بین کلمات را ثبت میکنند. - جاسازیهای سند:
کل اسناد یا بخشهای متنی را به صورت بردار نمایش میدهند. - جاسازیهای تصویر:
تصاویر را به صورت بردار نمایش میدهند و ویژگیها و مشخصات بصری را ثبت میکنند. - جاسازیهای صوتی:
ضبطهای صوتی را به صورت بردار نمایش میدهند و ویژگیها و الگوهای صدا را ثبت میکنند.
۴. مثالها:
Word2Vec، GloVe، FastText: الگوریتمهای محبوب برای ایجاد جاسازیهای کلمه.
BERT، تبدیلکنندههای جمله: مدلهای یادگیری عمیق که جاسازیهایی برای جملات و پاراگرافها ایجاد میکنند.
t-SNE: تکنیکی برای تجسم جاسازیهای با ابعاد بالا در فضای دوبعدی یا سهبعدی.
۵. ملاحظات کلیدی:
- اتلاف:
جاسازیها ممکن است برخی از جزئیات دادههای اصلی را سادهسازی یا از دست بدهند، اما این اغلب عمدی است تا روی مرتبطترین ویژگیها تمرکز شود. - هزینه محاسباتی:
آموزش و استفاده از جاسازیها میتواند از نظر محاسباتی گران باشد، به خصوص برای مجموعه دادههای بزرگ و مدلهای پیچیده. - ابعاد:
اندازه بردار جاسازی میتواند بسته به پیچیدگی مدل و دادهها متفاوت باشد.
جاسازی داده ها در یادگیری ماشینی چیستند؟
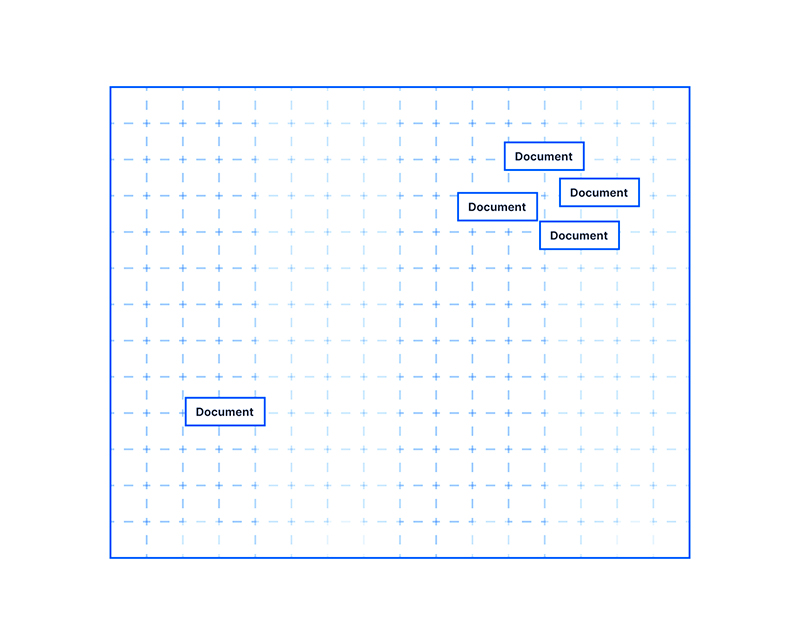
جاسازی داده ها بازنماییهایی از مقادیر یا اشیایی مانند متن، تصاویر و صدا هستند که برای استفاده توسط مدلهای یادگیری ماشین و الگوریتمهای جستجوی معنایی طراحی شدهاند. آنها اشیایی مانند اینها را بر اساس عوامل یا ویژگیهایی که هر کدام ممکن است داشته باشند یا نداشته باشند و دستههایی که به آنها تعلق دارند، به یک شکل ریاضی تبدیل میکنند.
اساساً، جاسازیها مدلهای یادگیری ماشین را قادر میسازند تا اشیاء مشابه را پیدا کنند. با توجه به یک عکس یا یک سند، یک مدل یادگیری ماشین که از جاسازیها استفاده میکند، میتواند یک عکس یا سند مشابه را پیدا کند. از آنجایی که جاسازیها به کامپیوترها امکان میدهند روابط بین کلمات و اشیاء دیگر را درک کنند، برای هوش مصنوعی (AI) اساسی هستند.
به عنوان مثال، اسناد موجود در سمت راست بالای این فضای دو بعدی ممکن است به یکدیگر مرتبط باشند:
از نظر فنی، جاسازیها بردارهایی هستند که توسط مدلهای یادگیری ماشین به منظور ثبت دادههای معنادار در مورد هر شیء ایجاد میشوند.
بردار در یادگیری ماشین چیست؟
در ریاضیات، بردار آرایهای از اعداد است که یک نقطه را در یک فضای بُعدی تعریف میکند. به عبارت عملیتر، بردار فهرستی از اعداد است – مانند {1989، 22، 9، 180}. هر عدد نشان میدهد که شیء در امتداد یک بُعد مشخص قرار دارد.
در یادگیری ماشین، استفاده از بردارها امکان جستجوی اشیاء مشابه را فراهم میکند. یک الگوریتم جستجوی بردار به سادگی باید دو بردار نزدیک به هم را در یک پایگاه داده برداری پیدا کند.
برای درک بهتر این موضوع، به عرض جغرافیایی و طول جغرافیایی فکر کنید. این دو بُعد – به ترتیب شمال-جنوب و شرق-غرب – میتوانند موقعیت هر مکانی را روی زمین نشان دهند. شهر ونکوور، بریتیش کلمبیا، کانادا را میتوان به صورت مختصات عرض جغرافیایی و طول جغرافیایی {49°15’40″N، 123°06’50″W} نشان داد. این فهرست از دو مقدار، یک بردار ساده است.
حال، تصور کنید که سعی میکنید شهری را پیدا کنید که بسیار نزدیک به ونکوور باشد. یک شخص فقط به یک نقشه نگاه میکند، در حالی که یک مدل یادگیری ماشین میتواند به جای آن به عرض و طول جغرافیایی (یا بردار) نگاه کند و مکانی با عرض و طول جغرافیایی مشابه پیدا کند. شهر برنابی در موقعیت {49°16’N, 122°58’W} قرار دارد – بسیار نزدیک به {49°15’40″N, 123°06’50″W}. بنابراین، مدل میتواند به درستی نتیجه بگیرد که برنابی در نزدیکی ونکوور واقع شده است.
اضافه کردن ابعاد بیشتر به بردارها
حال، تصور کنید که سعی میکنید شهری را پیدا کنید که نه تنها نزدیک به ونکوور باشد، بلکه اندازه مشابهی داشته باشد. به این مدل از مکانها، بیایید یک “بعد” سوم به عرض و طول جغرافیایی اضافه کنیم: اندازه جمعیت. جمعیت را میتوان به بردار هر شهر اضافه کرد و اندازه جمعیت را میتوان مانند محور Z در نظر گرفت، با عرض و طول جغرافیایی به عنوان محورهای Y و X.
بردار ونکوور اکنون {۴۹°۱۵’۴۰”شمالی، ۱۲۳°۰۶’۵۰”غربی، ۶۶۲,۲۴۸*} است. با اضافه شدن این بُعد سوم، برنابی دیگر به ونکوور خیلی نزدیک نیست، زیرا جمعیت آن تنها ۲۴۹,۱۲۵* است. در عوض، این مدل ممکن است شهر سیاتل، واشنگتن، ایالات متحده را پیدا کند که دارای برداری {۴۷°۳۶’۳۵”شمالی ۱۲۲°۱۹’۵۹”غربی، ۷۴۹,۲۵۶**} است.
*از سال ۲۰۲۱.
**از سال ۲۰۲۲.
این یک مثال نسبتاً ساده از نحوه عملکرد بردارها و جستجوی شباهت است. اما برای استفاده، مدلهای یادگیری ماشین ممکن است بخواهند بیش از سه بعد تولید کنند که منجر به بردارهای بسیار پیچیدهتری میشود.
جاسازی داده ها چگونه کار میکنند؟
جاسازی فرآیند ایجاد بردارها با استفاده از یادگیری عمیق است. “جاسازی” خروجی این فرآیند است – به عبارت دیگر، برداری که توسط یک مدل یادگیری عمیق به منظور جستجوی شباهت توسط آن مدل ایجاد میشود.
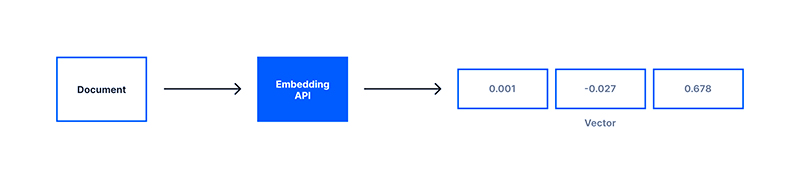
جاسازیهایی که به یکدیگر نزدیک هستند – درست همانطور که سیاتل و ونکوور مقادیر طول و عرض جغرافیایی نزدیک به یکدیگر و جمعیتهای قابل مقایسهای دارند – میتوانند مشابه در نظر گرفته شوند. با استفاده از جاسازیها، یک الگوریتم میتواند یک برنامه تلویزیونی مرتبط را پیشنهاد دهد، مکانهای مشابه را پیدا کند یا کلماتی را که احتمالاً با هم یا شبیه به یکدیگر استفاده میشوند، مانند مدلهای زبانی، شناسایی کند.
نحوه ایجاد جاسازیها توسط شبکههای عصبی
شبکههای عصبی مدلهای یادگیری عمیقی هستند که از معماری مغز انسان تقلید میکنند. همانطور که مغز از نورونهایی تشکیل شده است که تکانههای الکتریکی را به یکدیگر شلیک میکنند، شبکههای عصبی نیز از گرههای مجازی تشکیل شدهاند که وقتی ورودیهایشان از یک آستانه مشخص عبور میکند، با یکدیگر ارتباط برقرار میکنند.
شبکههای عصبی از چندین لایه ساخته شدهاند: یک لایه ورودی، یک لایه خروجی و هر تعداد لایه “پنهان” بین آنها. لایههای پنهان میتوانند ورودیها را به روشهای مختلفی تبدیل کنند، صرف نظر از اینکه مدل تعریف شده باشد.
ایجاد جاسازیها یک لایه پنهان است. این کار معمولاً قبل از پردازش ورودی توسط لایههای اضافی انجام میشود. بنابراین، برای مثال، یک انسان نیازی به تعریف محل قرارگیری هر برنامه تلویزیونی در صد بعد مختلف ندارد. در عوض، یک لایه پنهان در شبکه عصبی این کار را به طور خودکار انجام میدهد. سپس میتوان برنامه تلویزیونی را با استفاده از این جاسازی توسط لایههای پنهان دیگر تجزیه و تحلیل کرد تا برنامههای تلویزیونی مشابه پیدا شوند. در نهایت، لایه خروجی میتواند پیشنهادهایی از برنامههای دیگری که بینندگان ممکن است بخواهند تماشا کنند، ارائه دهد.
ایجاد این لایه جاسازی در ابتدا نیاز به کمی تلاش دستی دارد. یک برنامهنویس ممکن است مثالهایی از نحوه ایجاد یک جاسازی، ابعادی که باید در نظر گرفته شوند و غیره را به شبکه عصبی بدهد. در نهایت، لایه جاسازی میتواند به تنهایی عمل کند – اگرچه برنامهنویس ممکن است به تنظیم دقیق مدل برای ارائه توصیههای بهتر ادامه دهد.
چگونه از جاسازیها در مدلهای زبانی بزرگ (LLM) استفاده میشود؟
برای مدلهای زبانی بزرگ (LLM)، مانند مدلهایی که برای ابزارهای هوش مصنوعی مانند ChatGPT استفاده میشوند، جاسازی یک گام فراتر میرود. متن هر کلمه، علاوه بر خود کلمه، به یک جاسازی تبدیل میشود. معانی کل جملات، پاراگرافها و مقالات را میتوان جستجو و تجزیه و تحلیل کرد. اگرچه این کار به قدرت محاسباتی زیادی نیاز دارد، اما میتوان زمینه جستجوها را به عنوان جاسازی ذخیره کرد و در زمان و قدرت محاسباتی برای جستجوهای آینده صرفهجویی کرد.
مقاله های مرتبط:
1– مقدمه ای بر شبکه عصبی کانولوشن Convolution (CNN)
2- پردازش زبان طبیعی (NLP) در مقابل یادگیری ماشینی
3- حداقل سازی داده چه کاربردی دارد؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها