
Recurrent Neural Networks (شبکههای عصبی بازگشتی): حافظه قدرتمند برای دادههای ترتیبی
در دل پیشرفتهای شگرف یادگیری عمیق (Deep Learning)، Recurrent Neural Networks (RNNs) یا شبکههای عصبی بازگشتی به عنوان معماریای منحصربهفرد ظاهر شدهاند که به طور خاص برای پردازش دادههای ترتیبی (Sequential Data) طراحی شدهاند. دادههای ترتیبی به دادههایی گفته میشود که ترتیب آنها مهم است و هر عنصر در دنباله به عناصر قبلی و بعدی وابسته است. مثالهایی از این نوع دادهها شامل متن، صدا، سریهای زمانی (مانند قیمت سهام) و ویدئو میشوند.
اگر شبکههای عصبی سنتی (Feedforward Neural Networks) هر نمونه ورودی را به صورت مستقل پردازش میکنند و هیچ “حافظهای” از ورودیهای قبلی ندارند، RNNs با معرفی مفهوم “حالت مخفی” (Hidden State) این محدودیت را برطرف کردهاند. این حالت مخفی به شبکه اجازه میدهد تا اطلاعات مربوط به ورودیهای پیشین را حفظ کرده و در پردازش ورودیهای بعدی از آن استفاده کند. در این مقاله به بررسی جامع Recurrent Neural Networks، معماری آنها، نحوه عملکرد و کاربردهایشان میپردازیم.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
معماری Recurrent Neural Networks: حلقههای بازگشتی و حالت مخفی
ویژگی کلیدی که RNNs را از شبکههای عصبی معمولی متمایز میکند، وجود حلقههای بازگشتی (Recurrent Connections) است. این حلقهها به شبکه اجازه میدهند تا اطلاعات را از یک مرحله زمانی به مرحله زمانی بعدی منتقل کند.
تصور کنید یک RNN در حال پردازش یک جمله است. وقتی کلمه اول به شبکه وارد میشود، شبکه آن را پردازش کرده و یک حالت مخفی تولید میکند. این حالت مخفی نه تنها اطلاعات مربوط به کلمه اول را در خود دارد، بلکه به عنوان یک “حافظه” به مرحله زمانی بعدی منتقل میشود. وقتی کلمه دوم وارد میشود، شبکه آن را همراه با حالت مخفی ناشی از کلمه اول پردازش میکند و یک حالت مخفی جدید تولید میکند که هم اطلاعات کلمه دوم و هم خلاصهای از اطلاعات کلمه اول را در خود دارد. این فرآیند برای تمام کلمات جمله تکرار میشود.
هر مرحله زمانی در یک RNN، یک ورودی (مثلاً یک کلمه در یک جمله) و حالت مخفی قبلی را دریافت میکند. شبکه سپس با استفاده از یک تابع فعالسازی (مانند tanh یا ReLU) یک حالت مخفی جدید و یک خروجی (که میتواند در برخی کاربردها پیشبینی باشد) را محاسبه میکند.
فرمولهای اساسی یک RNN ساده:
که در آن:
- : ورودی در مرحله زمانی
- : حالت مخفی در مرحله زمانی
- : حالت مخفی در مرحله زمانی قبلی
- : خروجی در مرحله زمانی
- : ماتریسهای وزن که در تمام مراحل زمانی به اشتراک گذاشته میشوند.
- : بردارهای بایاس
- : تابع فعالسازی برای حالت مخفی (معمولاً tanh یا ReLU)
- : تابع فعالسازی برای خروجی (بسته به نوع وظیفه، میتواند sigmoid, softmax یا یک تابع خطی باشد)
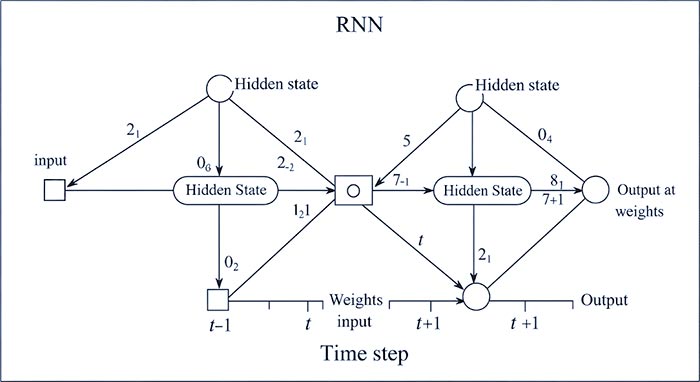
تصویر 1: شماتیک سادهای از یک RNN که در طول زمان باز شده است، نشاندهنده جریان اطلاعات و حالت مخفی از یک مرحله زمانی به مرحله زمانی دیگر.
چالشها در شبکههای عصبی بازگشتی سنتی: مشکل محو و انفجار گرادیان
با وجود قدرت RNNs در پردازش دادههای ترتیبی، شبکههای عصبی بازگشتی سنتی با چالشهای مهمی روبرو هستند، به ویژه مشکل محو گرادیان (Vanishing Gradient Problem) و انفجار گرادیان (Exploding Gradient Problem).
در طول فرآیند آموزش شبکههای عصبی با استفاده از الگوریتم پسانتشار در طول زمان (Backpropagation Through Time – BPTT)، گرادیانها برای بهروزرسانی وزنهای شبکه در طول دنباله زمانی به عقب منتشر میشوند. در دنبالههای طولانی، گرادیانها میتوانند به طور تصاعدی کوچک شوند (محو شوند) یا به طور تصاعدی بزرگ شوند (منفجر شوند).
-
محو گرادیان: وقتی گرادیانها بسیار کوچک میشوند، وزنهای لایههای اولیه (که اطلاعات مربوط به ورودیهای دورتر در دنباله را نگهداری میکنند) به سختی بهروزرسانی میشوند. این امر باعث میشود که شبکه در یادگیری وابستگیهای بلندمدت (Long-Term Dependencies) در دادههای ترتیبی دچار مشکل شود. به عنوان مثال، در یک جمله طولانی، شبکه ممکن است نتواند ارتباط بین اطلاعات ارائه شده در ابتدای جمله با کلمات پایانی را به خوبی یاد بگیرد.
-
انفجار گرادیان: در مقابل، وقتی گرادیانها بسیار بزرگ میشوند، میتوانند باعث نوسانات شدید در وزنهای شبکه و ناپایداری در فرآیند آموزش شوند.
معماریهای پیشرفته RNN: LSTM و GRU
برای مقابله با مشکلات محو و انفجار گرادیان، معماریهای پیشرفتهتری از RNNs توسعه داده شدهاند که از جمله مهمترین آنها میتوان به Long Short-Term Memory (LSTM) و Gated Recurrent Unit (GRU) اشاره کرد.
LSTM: شبکههای LSTM با معرفی “سلول حافظه” (Memory Cell) و سه نوع “دروازه” (Gates) – دروازه ورودی (Input Gate)، دروازه فراموشی (Forget Gate) و دروازه خروجی (Output Gate) – قادر به یادگیری وابستگیهای بلندمدت به طور مؤثرتری هستند. این دروازهها مکانیسمهایی را برای کنترل جریان اطلاعات به داخل و خارج از سلول حافظه فراهم میکنند و به شبکه اجازه میدهند تا تصمیم بگیرد کدام اطلاعات را حفظ کند و کدام را فراموش کند.
GRU: شبکههای GRU معماری سادهتری نسبت به LSTM دارند و تنها از دو دروازه – دروازه بهروزرسانی (Update Gate) و دروازه بازنشانی (Reset Gate) – استفاده میکنند. GRU نیز در یادگیری وابستگیهای بلندمدت عملکرد خوبی از خود نشان داده و در عین حال پارامترهای کمتری نسبت به LSTM دارد که میتواند منجر به آموزش سریعتر شود.
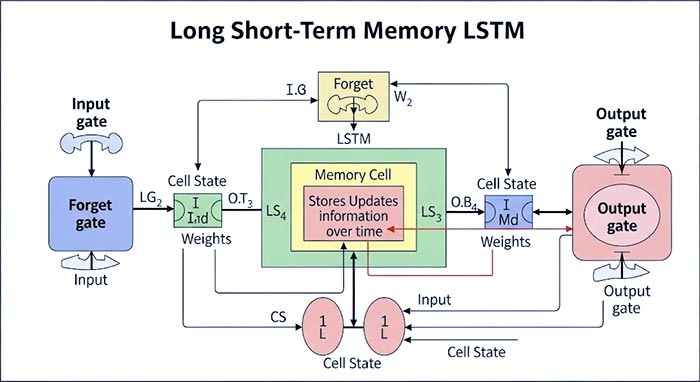
تصویر 2: معماری یک سلول LSTM که شامل دروازههای ورودی، فراموشی و خروجی و سلول حافظه است.
کاربردهای Recurrent Neural Networks
RNNs و مشتقات پیشرفته آنها (LSTM و GRU) در طیف گستردهای از کاربردها که شامل پردازش دادههای ترتیبی میشوند، عملکرد بسیار خوبی از خود نشان دادهاند:
- پردازش زبان طبیعی (Natural Language Processing – NLP):
- مدلسازی زبان (Language Modeling): پیشبینی کلمه بعدی در یک دنباله.
- ترجمه ماشینی (Machine Translation): تبدیل متن از یک زبان به زبان دیگر.
- تولید متن (Text Generation): تولید متنهای جدید (مانند شعر، داستان، یا کد).
- تحلیل احساسات (Sentiment Analysis): تعیین احساس (مثبت، منفی، خنثی) موجود در یک متن.
- خلاصهسازی متن (Text Summarization): تولید خلاصههای کوتاه از متون طولانی.
- تشخیص گفتار (Speech Recognition): تبدیل صدای گفتار به متن.
- تولید صدا (Speech Synthesis): تبدیل متن به صدای گفتار.
- سریهای زمانی (Time Series Analysis):
- پیشبینی قیمت سهام: پیشبینی تغییرات قیمت سهام در طول زمان.
- پیشبینی آب و هوا: پیشبینی شرایط جوی آینده.
- تشخیص ناهنجاری در دادههای سری زمانی.
- پردازش ویدئو: تحلیل محتوای ویدئو در طول زمان.
- موسیقی: تولید موسیقی.
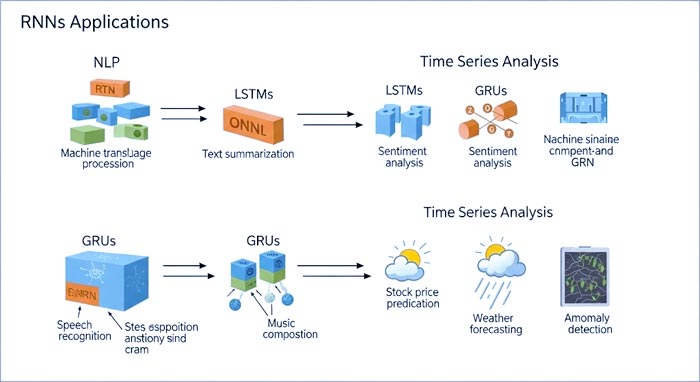
تصویر 3: کاربردهای متنوع RNNs در حوزههای مختلف از پردازش زبان طبیعی تا تحلیل سریهای زمانی.
نتیجهگیری
Recurrent Neural Networks (شبکههای عصبی بازگشتی) با توانایی حفظ “حافظه” از طریق حالت مخفی و معماری بازگشتی خود، ابزاری قدرتمند برای پردازش دادههای ترتیبی به شمار میروند. در حالی که RNNs سنتی با مشکلاتی مانند محو و انفجار گرادیان روبرو بودند، معماریهای پیشرفتهای نظیر LSTM و GRU این چالشها را به طور قابل توجهی کاهش دادهاند و امکان یادگیری وابستگیهای بلندمدت را فراهم کردهاند. با کاربردهای گسترده در زمینههایی مانند NLP، تشخیص گفتار و تحلیل سریهای زمانی، شبکههای عصبی بازگشتی همچنان در خط مقدم تحقیقات یادگیری عمیق قرار دارند و نقش مهمی در توسعه سیستمهای هوشمند ایفا میکنند. درک عمیق این شبکهها برای هر علاقهمند به حوزه یادگیری ماشین و پردازش دادههای ترتیبی ضروری است.
مقاله های مرتبط:
1- Logistic Regression (رگرسیون لجستیک) در یادگیری ماشین چیست؟
2- Decision Tree (درخت تصمیم) چیست؟
3- 6 مرحله برای فعال کردن ارزش متن به نمودار سیستم های یادگیری ماشین
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها