
این وبلاگ نحوه ساخت خط لوله یادگیری ماشینی از متن به نمودار را توضیح می دهد تا قدرت داده های متنی و نمودارها را در کنار هم قرار دهد. هماهنگ کردن این دو تکنیک گام بعدی را در تکامل یادگیری ماشینی به عنوان پردازش زبان طبیعی (NLP) و نظریه گراف فراهم میکند که در چند سال گذشته دو رشته از سریعترین رشد در علم داده باقی ماندهاند.
چرا یادگیری ماشینی متن به نمودار؟
دلایل زیادی وجود دارد، اما اصلی ترین آنها اثربخشی NLP است. در حالی که این دو حوزه میتوانند مستقل از یکدیگر عمل کنند، به دلیل ارزشی که نمودار برای NLP به ارمغان میآورد، یک سوال طبیعی در مورد چگونگی استفاده از ارزش یادگیری ماشین گراف برای هدایت ارزش بیشتر از اسناد متنی به مدل یادگیری ماشین گراف پدیدار میشود. یادگیری ماشینی نوشتار به نمودار همچنین یک بلوک اساسی برای نحوه ایجاد یک نمودار دانش است که هر سال به موضوعی مهم تر تبدیل می شود.
یک رابط زبان طبیعی جدید و قدرتمند برای پایگاه داده گراف / نمودار دانش خود را بررسی کنید که به کاربران غیر فنی شما امکان می دهد سوالات زبان طبیعی را مستقیماً از خود پایگاه داده بپرسند.
جاسازی متن
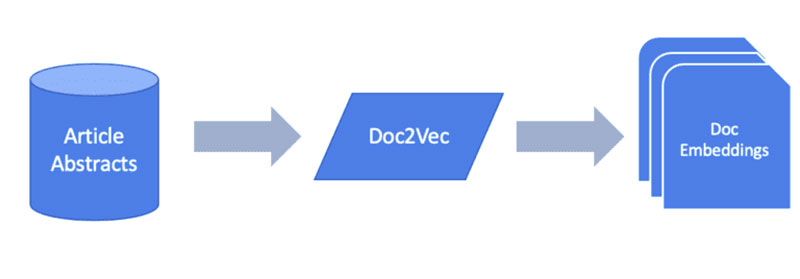
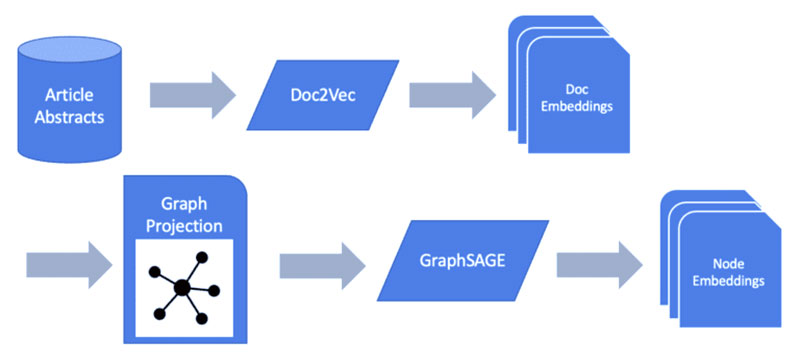
قبل از اینکه بتوانیم نمودارهای خود را با اطلاعات متن خود القا کنیم، ابتدا باید معنی و مقدار ذخیره شده را از آنها استخراج کنیم. برای انجام این کار، یک مدل جاسازی ساده برای تولید بردارهای ویژگی برای هر نمونه از متن پیاده سازی می کنیم. این می تواند برای تک تک کلمات باشد، همانطور که اگر ما علاقه مند به مقایسه چکیده ها و معنای نشریات یا اسناد دیگر باشیم، کلمات کلیدی منفرد از نشریات پزشکی یا حتی کل اسناد را تجزیه و تحلیل می کنیم.
در این مثال، فرض میکنیم که علاقه مند به درک چگونگی ارتباط نشریات مختلف با یکدیگر بر اساس متن چکیدهها و شبکه مرتبط با نویسندگان هستیم.
ما میتوانیم این کار را با تعدادی مدل یا خدمات مختلف انجام دهیم، در زیر تعدادی از رایجترین آنها را فهرست کردهایم:
جاسازی های کلمه
- TF-IDF
- Word2Vec
- BERT
جاسازی اسناد
- Doc2Vec
- AWS SageMaker Object2Vec
- Word Mover’s Embedding (WME)
- SBERT
اکنون که جاسازیهای سند خود را ایجاد کردهایم، میتوانیم بخش یادگیری ماشین نمودار مشکل خود را بررسی کنیم.
تنظیم صحنه با Projection مناسب
قبل از اینکه بتوانیم مدل ML گراف خود را با تعبیههای سند خود آموزش دهیم، ابتدا باید طرح نموداری را که بر روی آن آموزش میدهد، توضیح دهیم. اگر مقاله ما درمورد نمودار دانش چیست را بخوانید، میبینید که ذخیرهگاه دادههای گراف بومی که استفاده میکنید ممکن است علاوه بر مقالهها و نویسندگان، شامل چندین نوع گره باشد که بسیاری از آنها میتوانند به آن مقالات و نویسندگان متصل شوند. به همین دلیل، ابتدا باید دادههای گراف خود را در گرهها و روابطی که با مشکل مورد نظر مرتبط هستند، تقطیر کنیم.
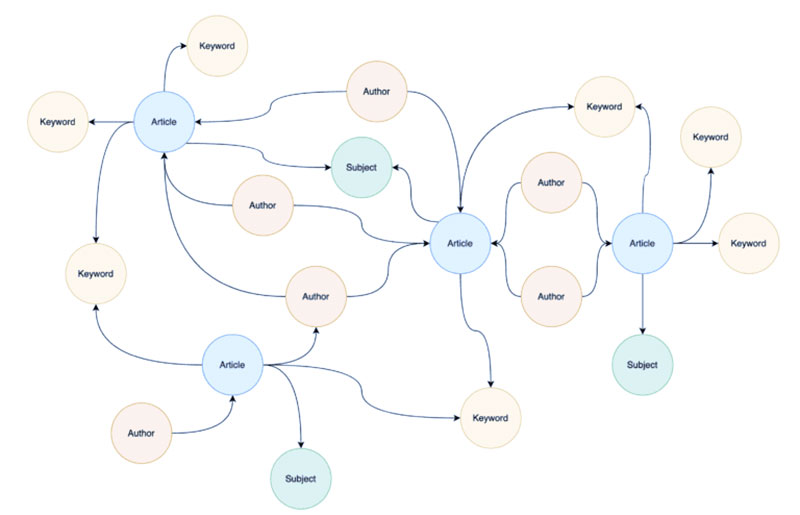
ما با نادیده گرفتن بقیه نمودار دانش شروع می کنیم تا به طور انحصاری بر گره های نویسنده، گره های مقاله / article و روابطی که آنها را به هم وصل می کنند تمرکز کنیم تا یک طرح دوبخشی از نمودار ما به دست آید.
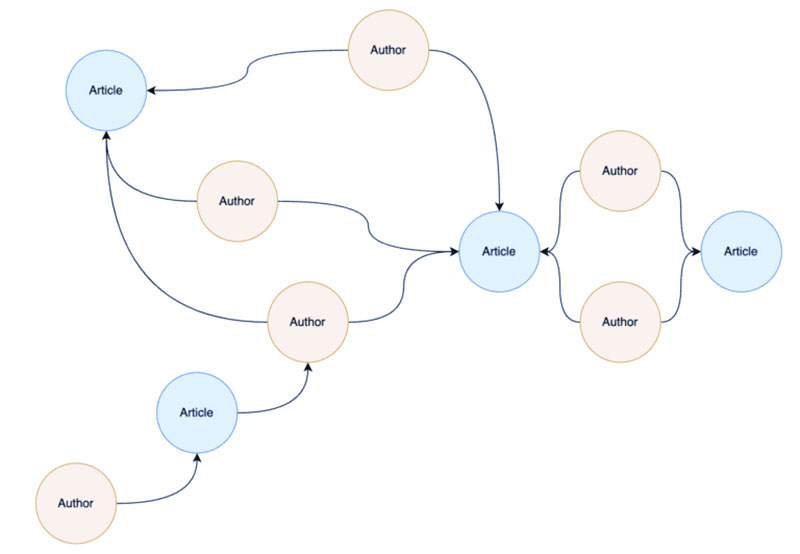
در مرحله بعد، یک وزن رابطه تعریف میکنیم تا نشان دهیم کدام روابط قویتر از سایرین هستند، سپس این نمودار دوبخشی را به یک نمودار تکبخشی از مقالهها “fold ” میکنیم که وزن هر رابطه بر اساس تعداد نویسندگان مشترک دو مقاله تعیین میشود.
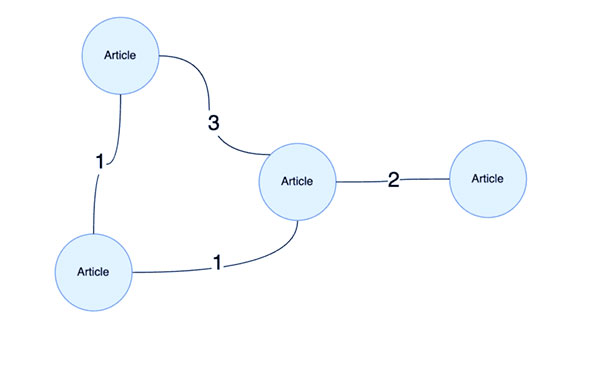
در مرحله بعد، با ایجاد طرح ریزی ما، باید در نظر بگیریم که از کدام مدل گراف ML در متن خود برای ترسیم خط لوله یادگیری ماشین استفاده کنیم.
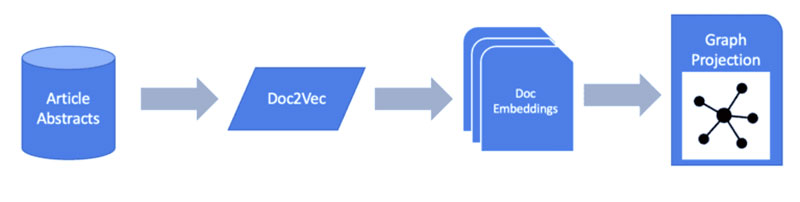
انتخاب مدل یادگیری ماشین گراف
اکنون که دادههای انتشار خود را در یک فضای تعبیهشده نشان میدهیم، و طرحبندی نمودار ما ایجاد شده است، میتوانیم به نحوه تغذیه آنها در پایین دست به یک مدل یادگیری ماشین گراف فکر کنیم. با این حال، نه تنها هر مدل گراف ML این کار را انجام می دهد، ما باید آنهایی را در نظر بگیریم که می توانند مجموعه ای از بردارهای ویژگی را بپذیرند.
بسیاری از مدلهای اولیه گراف ML که از مجاورت توپولوژیکی یا پیادهروی تصادفی برای تولید معیارهای شباهت استفاده میکنند، منحصراً به اتصالات بین مجموعهای از گرهها برای تولید نمایش برداری از هر گره در نمودار متکی هستند. از آنجایی که این روشها از هیچ ویژگی گرهی در محاسبات خود استفاده نمیکنند، برای کار در دست مناسب نیستند. در عوض، ما باید بر روی آن معماریهای مدل تکیه کنیم که ویژگیهای گره را به عنوان بخشی از طراحی خود میپذیرند. یک بار دیگر، ما برخی از گزینه های محبوب برای چنین کاری را فهرست کرده ایم:
- Graph Convolutional Network (GCN)
- GraphSAGE
- Graph ATtention Network (GAT)
در مثال خود، از GraphSAGE در متن خود برای ترسیم نمودار خط لوله یادگیری ماشین استفاده می کنیم.
در نهایت، با انتخاب معماری مدل ما، میتوانیم شروع به آموزش کنیم و به نتایجی دست یابیم.
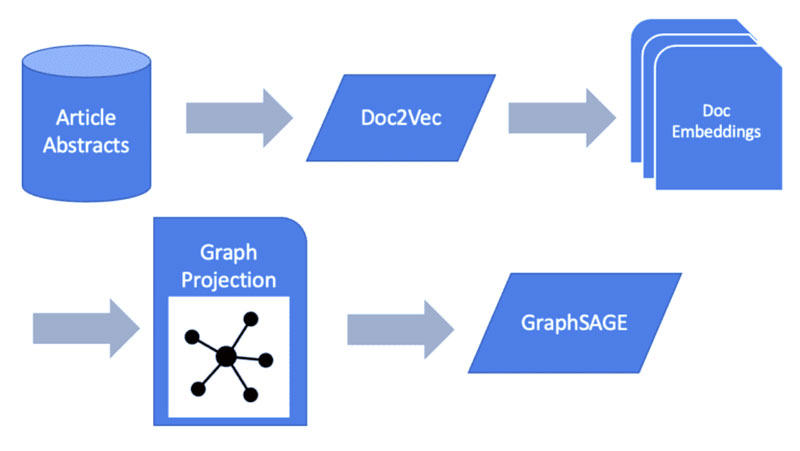
انتقال متن به نمودار مدل های یادگیری ماشین
برای اینکه هم شباهت سند و هم شباهت شبکه مشترک نویسندگی را در اسناد خود ثبت کنیم، بیایید با ایجاد نمایش گره برای هر یک از اسناد خود، متن خود را تکمیل کنیم تا خط لوله یادگیری ماشین را نمودار کنیم.
ابتدا، بیایید مطمئن شویم که طرح تکبخشی ما شامل همه جاسازیهای سندی است که قبلاً به عنوان ویژگیهای گره ایجاد کردیم.
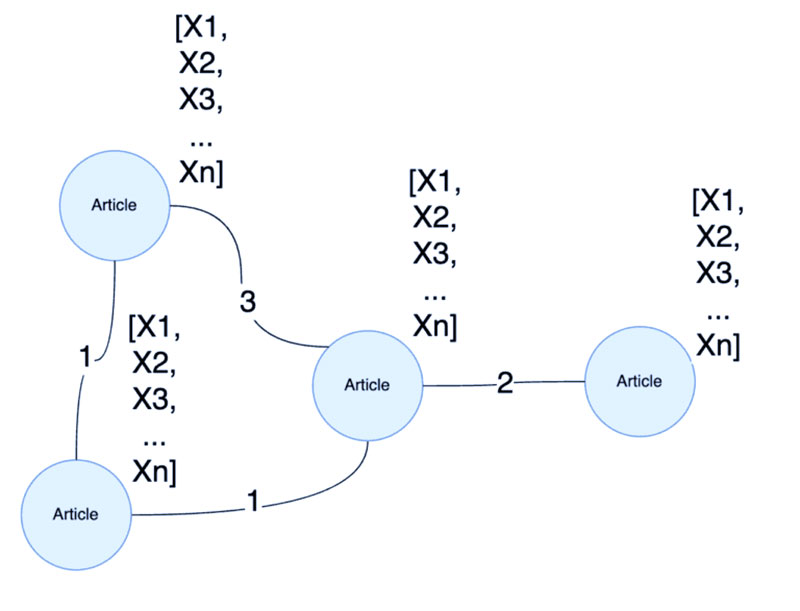
در مرحله بعد، مدل GraphSAGE خود را در برابر طرح با K = 2 آموزش خواهیم داد تا ارسال پیام را به دو درجه جداسازی محدود کنیم. این باید یک جریان انتقال پیام پایدار بین مقالات را به ما بدهد.
این معماری ارسال پیام باعث می شود هر مقاله ای که به یکدیگر متصل است اطلاعات ویژگی های خود را بین یکدیگر به اشتراک بگذارد. از این طریق، ما اطلاعات جمعآوریشده توسط مدل جاسازی سند را بر اساس تعداد نویسندگانی که آنها به اشتراک گذاشتهاند، به اسناد دیگر منتقل میکنیم. این انتقال اطلاعات سپس به سایر همسایگان و همچنین همسایگان آنها گسترش می یابد تا فضای جاسازی را ایجاد کند که حاوی نمایش نهایی ما از مقالات است.
ابزار یادگیری ماشینی مبتنی بر متن
با ایجاد جاسازیهایمان، اکنون مجموعهای از اسناد داریم که به صورت بردار با استفاده از شباهت متنی زیربنایی و اتصال همنویسندگی آنها ارائه شدهاند. این به ما مجموعه ای از جاسازی های بسیار آگاهانه را ارائه می دهد که می توانند برای تعدادی از وظایف پایین دستی استفاده شوند. بیایید چند مورد را بررسی کنیم.
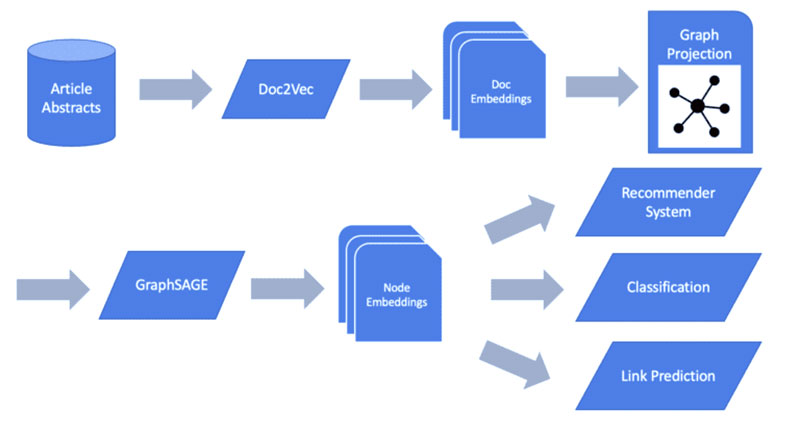
خوشه بندی برای سیستم های توصیه کننده
در حالی که سادهترین گزینه، یک خوشه ساده KNN به ما امکان میدهد تا اندازهگیری کنیم که کدام اسناد در فضای جاسازی بیشتر شبیه یکدیگر هستند. با استفاده از این معیار، ما به راحتی میتوانیم یک توصیه «Top N» را بر اساس نزدیکترین همسایگان برای یک مقاله ارائه کنیم.
طبقه بندی
یکی از قدرتمندترین وظایف نهایی برای خط لوله یادگیری ماشینی ما برای نمودارسازی متن، تغذیه جاسازیهای ما به یک مدل طبقهبندیکننده نهایی مانند رگرسیون لجستیک، جنگل تصادفی یا XGBoost است. این به ما امکان میدهد از برچسبهای تاریخی استفاده کنیم تا طبقهبندی کنیم که یک مقاله ممکن است با کدام موضوع مرتبط باشد.
پیش بینی لینک
در نهایت، میتوانیم به دنبال پیشبینی روابط غیر موجود در نمودار خود باشیم. در این زمینه، وقتی نوبت به یافتن مجموعههایی از نویسندگانی میرسد که ممکن است بخواهند در آینده با هم تحقیق کنند، میتوانیم از آن برای پیشبینی پیوند استفاده کنیم.
نتیجه گیری
در حالی که یادگیری ماشینی از متن به نمودار تنها راه برای انجام NLP نیست، به دلیل نقاط قوت منحصر به فرد پایگاه داده گراف، به سرعت در حال تبدیل شدن به موثرترین و ارزشمندترین روش است. با ترکیب مقدار منحصربهفرد هر دو فیلد، اکنون یک راه قدرتمندتر و مقیاسپذیرتر برای افزایش ارزش از تمام دادههای متنی شما وجود دارد.
مقاله های مرتبط:
1- مقدمه ای بر شبکه عصبی کانولوشن Convolution (CNN)
2- بهترین کتابخانه های پایتون برای یادگیری ماشین
3- کدام پایگاه داده برای یادگیری ماشینی بهتر است؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها