

داده های اسمی Nominal Data چیست ؟
داده های اسمی که به عنوان دادههای طبقهای نیز شناخته میشوند، نوعی داده است که در آمار برای برچسبگذاری متغیرها بدون ارائه هیچ مقدار کمی استفاده میشود. ویژگی کلیدی داده های اسمی این است که داده ها را در گروه های مجزا دسته بندی می کند که ترتیب یا رتبه بندی خاصی ندارند. این بدان معنی است که در حالی که داده ها را می توان به دسته ها تقسیم کرد، این دسته ها را نمی توان به طور معناداری در یک ترتیب سلسله مراتبی مرتب کرد.
برای مثال، متغیر «طعم بستنی مورد علاقه» را در نظر بگیرید. دسته بندی های ممکن می تواند شکلات، وانیل و توت فرنگی باشد. این دسته بندی ها نظم ذاتی ندارند – شکلات ذاتا “بهتر” یا “بدتر” از وانیل یا توت فرنگی نیست.
در این مقاله به این مفهوم از داده های اسمی شامل مثال ها و روش های جمع آوری می پردازیم.
داده های اسمی چیست؟
دادههای اسمی نوعی از دادههای طبقهبندی هستند که در آن دستهها متمایز هستند و هیچ ترتیب یا رتبهبندی ذاتی ندارند. برای برچسب گذاری یا نامگذاری متغیرها بدون اختصاص مقدار کمی به آنها استفاده می شود. هر مقدار در دادههای اسمی متقابلاً انحصاری است، به این معنی که هیچ مورد منفردی نمیتواند به بیش از یک دسته تعلق داشته باشد.
داده های اسمی برای برچسب گذاری متغیرها بدون هیچ مقدار کمی استفاده می شود. به عنوان مثال می توان به جنسیت (مرد، زن)، رنگ چشم (آبی، سبز، قهوه ای) و انواع غذاهای (ایتالیایی، چینی، مکزیکی) اشاره کرد.
تعریف داده های اسمی
داده های اسمی، که به عنوان داده های طبقه بندی نیز شناخته می شوند، نوعی داده است که برای برچسب گذاری متغیرها بدون ارائه هیچ مقدار کمی استفاده می شود.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
ویژگی های داده های اسمی
- داده های اسمی نشان دهنده دسته ها یا نام ها هستند. هر مقدار در داده های اسمی متمایز است و در یک دسته بندی خاص قرار می گیرد.
- دسته بندی ها در داده های اسمی ترتیب یا رتبه بندی خاصی ندارند. یک دسته بالاتر یا پایین تر از دسته دیگر در نظر گرفته نمی شود.
- هر مشاهده متعلق به یک و تنها یک دسته است. هیچ همپوشانی بین دسته ها وجود ندارد.
- عملیات حسابی مانند جمع، تفریق، ضرب یا تقسیم را نمی توان روی داده های اسمی انجام داد.
- داده های اسمی کیفی هستند، به این معنی که به جای کمیت، کیفیت ها یا ویژگی ها را توصیف می کنند.
نمونه هایی از داده های اسمی
چند نمونه از داده های اسمی عبارتند از:
- جنسیت: مذکر، مؤنث، غیر باینری، دیگر
- وضعیت تاهل: مجرد، متاهل، مطلقه، بیوه
- ملیت: آمریکایی، کانادایی، هندی، چینی، استرالیایی و غیره
- گروه خونی: A، B، AB، O
- رنگ چشم: قهوه ای، آبی، سبز، فندقی، مشکی
- برند خودرو: تویوتا، فورد، هوندا، بیامو، تسلا
- انواع غذا: ایتالیایی، مکزیکی، چینی، هندی، تایلندی
- حزب سیاسی: دموکرات، جمهوری خواه، مستقل، سبز
- انواع حیوانات خانگی: سگ، گربه، ماهی، پرنده، همستر
- ورزش مورد علاقه: فوتبال، بسکتبال، تنیس، کریکت، بیسبال
چگونه داده های اسمی را جمع آوری کنیم؟
جمعآوری دادههای اسمی شامل جمعآوری اطلاعاتی است که میتوانند بدون مقدار یا ترتیب عددی دستهبندی شوند. در اینجا چند روش برای جمع آوری داده های اسمی وجود دارد:
- نظرسنجی ها و پرسشنامه ها: نظرسنجی هایی با سوالات چند گزینه ای طراحی کنید که در آن پاسخ دهندگان پاسخ های خود را از دسته های از پیش تعریف شده انتخاب می کنند.
مثال: “نوع غذای مورد علاقه شما چیست؟” با گزینه هایی مانند ایتالیایی، مکزیکی، چینی، هندی و غیره.
- مصاحبهها: مصاحبههای ساختاریافته یا نیمهساختیافته با پرسشهایی که برای برانگیختن پاسخهای طبقهبندی شدهاند، انجام دهید.
مثال: پرسش از مصاحبه شوندگان در مورد وضعیت تأهل یا وابستگی سیاسی آنها.
- مشاهده: مشاهده و ثبت داده ها بر اساس دسته بندی های قابل مشاهده.
مثال: توجه به انواع خودروهای موجود در پارکینگ (تویوتا، فورد، هوندا و …).
- سوابق اداری: از سوابق یا پایگاه های داده موجود که حاوی اطلاعات دسته بندی هستند استفاده کنید.
مثال: سوابق بیمارستانی با گروه خونی بیماران یا سوابق مؤسسات آموزشی رشته های دانشجویی.
- فرمهای آنلاین: فرمهای آنلاین را با منوهای کشویی یا دکمههای رادیویی برای سؤالات طبقهبندی ایجاد کنید.
مثال: یک فرم ثبت نام آنلاین که جنسیت را با گزینه های مذکر، مونث، غیر باینری، دیگر درخواست می کند.
تکنیک های تجسم برای داده های اسمی
برخی از تکنیک های رایج برای تجسم برای داده های اسمی عبارتند از:
- جداول فرکانس
- نمودارهای میله ای
- نمودارهای دایره ای
جداول فرکانس
جداول فراوانی دسته ها و تعداد یا فرکانس مربوط به آنها را فهرست می کند. در حالی که یک روش گرافیکی نیست، آنها خلاصه ای واضح و دقیق از داده ها را ارائه می دهند.
به عنوان مثال، اگر در پرسشنامهای از 100 نفر در مورد غذای مورد علاقهشان از «سیب، موز، اورنگ، استاربری، انگور» سؤال شود، به عنوان مثال،
توت فرنگی، انگور، انگور، انگور، انگور، سیب، انگور، توت فرنگی، انگور، پرتقال، انگور، پرتقال، سیب، موز، موز، موز، سیب، سیب، موز، سیب، پرتقال، انگور، موز، موز، انگور، موز، سیب، انگور، موز، انگور، موز، توت فرنگی، موز، توت فرنگی، انگور، موز، سیب، پرتقال، انگور، سیب، پرتقال، موز، توت فرنگی، موز، پرتقال، سیب، موز، سیب، پرتقال، پرتقال، موز، توت فرنگی، موز، موز، توت فرنگی، توت فرنگی، موز، سیب، سیب، موز، انگور، توت فرنگی، انگور، سیب، انگور، پرتقال، سیب، موز، سیب، سیب، موز، سیب، موز، سیب، موز، سیب، موز، پرتقال، موز، پرتقال، موز، موز، سیب، توت فرنگی، پرتقال، سیب، انگور، موز، موز، سیب، انگور، پرتقال، سیب، موز، سیب، انگور، سیب، انگور، پرتقال، پرتقال
جدول فراوانی این داده ها به صورت زیر است:
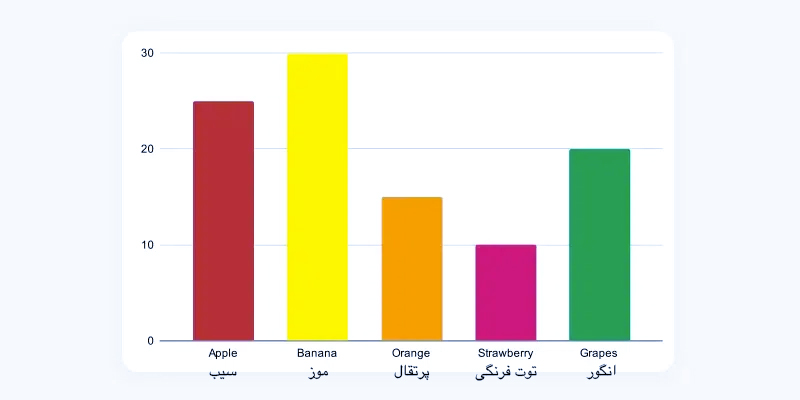
| میوه | تعداد |
| سیب | 25 |
| موز | 30 |
| پرتقال | 15 |
| توت فرنگی | 10 |
|
انگور |
20 |
نمودارهای میله ای
نمودار میله ای یکی از ساده ترین راه ها برای تجسم داده های اسمی است. هر دسته با یک نوار نشان داده می شود و طول یا ارتفاع میله با فرکانس یا تعداد آن دسته مطابقت دارد. این روش امکان مقایسه آسان بین دسته ها را فراهم می کند.
نمودار میله ای برای داده های فوق به شرح زیر است:
نمودارهای دایره ای
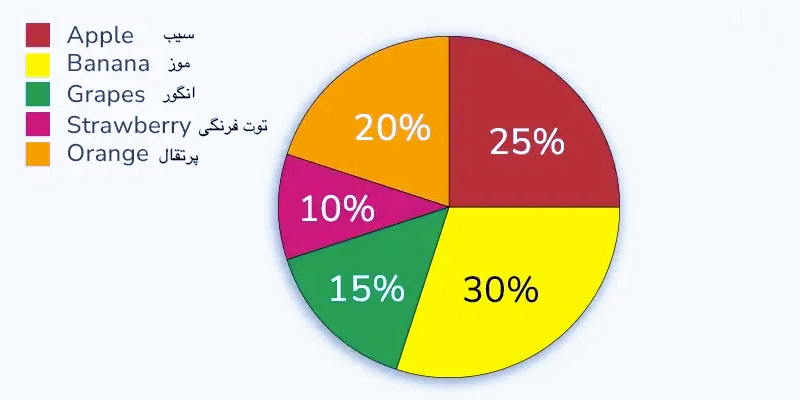
نمودارهای دایره ای داده ها را در قالب دایره ای نمایش می دهند که در آن هر برش نسبت یک دسته را نسبت به کل مجموعه داده نشان می دهد. این تجسم برای نشان دادن اجزای یک کل مفید است.
برای داده های مورد بحث در بالا می توانیم همان داده ها را نشان دهیم
| میوه | تعداد | محاسبه | درصد |
| سیب | 25 | (25/100)×100 | 25% |
| موز | 30 | (30/100)×100 | 30% |
| پرتقال | 15 | (15/100)×100 | 15% |
| توت فرنگی | 10 | (10/100)×100 | 10% |
| انگور | 20 | (20/100)×100 | 20% |
نمودار دایره ای برای این داده ها به صورت زیر است:
جدول مقایسه داده های اسمی و ترتیبی
| خصوصیات | Nominal data | Ordinal Data |
| ماهیت دسته بندی ها | متمایز و گسسته | گسسته و متمایز |
| سفارش / رتبه بندی | بدون نظم ذاتی | دارای ترتیب یا رتبه بندی مشخص است |
| مقادیر عددی | بدون مقادیر عددی معنی دار | بدون مقادیر عددی معنی دار |
| تکنیک های تحلیل | تعداد فراوانی، درصد، نمودار میله ای | رتبه بندی، میانه، آزمون های ناپارامتریک، نمودار میله ای مرتب، رگرسیون ترتیبی |
| نمونه | رنگ ها، جنسیت، انواع حیوانات | نمرات مدرسه، سطح تحصیلات، سطح ارشد |
| تفسیر | برای طبقه بندی و گروه بندی بر اساس دسته استفاده می شود | برای ارزیابی اولویتهای مرتب، سلسله مراتب یا رتبهبندی استفاده میشود |
نتیجه گیری
بهطور خلاصه، دادههای اسمی به طبقهبندی و برچسبگذاری متغیرها کمک میکنند و گروهبندی و مقایسه آسان را بدون دلالت بر مقدار یا ترتیب عددی امکانپذیر میسازند. این آن را به یک نوع داده اساسی برای بسیاری از زمینه ها، از جمله بازاریابی، مراقبت های بهداشتی و علوم اجتماعی تبدیل می کند.
مقاله های مرتبط:
1- مقایسه بین داده های اسمی / Nominal و داده های ترتیبی / Ordinal
2- جمع آوری داده ها | Data Collection چیست؟
3- معرفی انواع مدل های داده ای یا Data Model
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها