
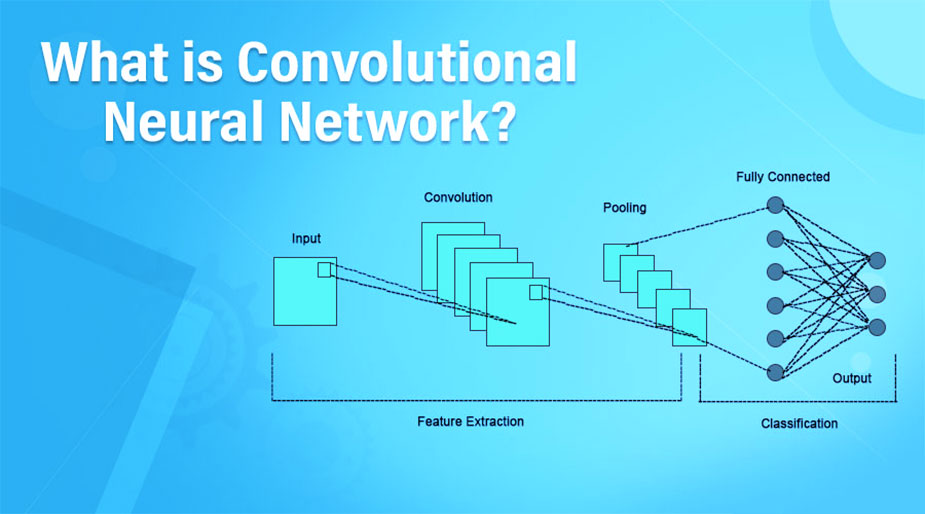
شبکه عصبی کانولوشن Convolution (CNN)
شبکه عصبی کانولوشنال (CNN) نوعی از معماری شبکه عصبی یادگیری عمیق است که معمولاً در بینایی رایانه استفاده می شود. بینایی کامپیوتر رشتهای از هوش مصنوعی است که کامپیوتر را قادر میسازد تا تصویر یا دادههای بصری را درک و تفسیر کند.
وقتی صحبت از یادگیری ماشینی می شود، شبکه های عصبی مصنوعی واقعاً خوب عمل می کنند. شبکه های عصبی در مجموعه داده های مختلفی مانند تصاویر، صدا و متن استفاده می شوند. انواع مختلف شبکه های عصبی برای اهداف مختلف استفاده می شود، به عنوان مثال برای پیش بینی توالی کلمات از شبکه های عصبی تکراری به طور دقیق تر از LSTM استفاده می کنیم، به طور مشابه برای طبقه بندی تصویر از شبکه های عصبی کانولوشن استفاده می کنیم. در این وبلاگ، ما قصد داریم یک بلوک اساسی برای CNN بسازیم.
شبکه های عصبی: لایه ها و عملکرد
در یک شبکه عصبی معمولی سه نوع لایه وجود دارد:
- لایه های ورودی: لایه ای است که در آن ورودی به مدل خود می دهیم. تعداد نورون های این لایه برابر است با تعداد کل ویژگی های داده های ما (تعداد پیکسل ها در مورد یک تصویر).
- لایه پنهان: ورودی لایه ورودی به لایه مخفی وارد می شود. بسته به مدل و اندازه داده ما می تواند لایه های پنهان زیادی وجود داشته باشد. هر لایه پنهان میتواند تعداد نورونهای مختلفی داشته باشد که عموماً از تعداد ویژگیها بیشتر است. خروجی هر لایه با ضرب ماتریسی خروجی لایه قبلی با وزن های قابل یادگیری آن لایه و سپس با اضافه کردن سوگیری های قابل یادگیری و به دنبال آن تابع فعال سازی که شبکه را غیرخطی می کند محاسبه می شود.
- لایه خروجی: خروجی از لایه پنهان سپس به یک تابع لجستیک مانند sigmoid یا softmax وارد می شود که خروجی هر کلاس را به امتیاز احتمال هر کلاس تبدیل می کند.
شبکه عصبی کانولوشن
شبکه عصبی کانولوشنال (CNN) نسخه توسعه یافته شبکه های عصبی مصنوعی (ANN) است که عمدتاً برای استخراج ویژگی از مجموعه داده ماتریس شبکه مانند استفاده می شود. به عنوان مثال مجموعه داده های بصری مانند تصاویر یا فیلم ها که در آن الگوهای داده نقش گسترده ای دارند.
معماری CNN
شبکه عصبی کانولوشن از چندین لایه مانند لایه ورودی، لایه کانولوشن، لایه ادغام و لایه های کاملاً متصل تشکیل شده است.
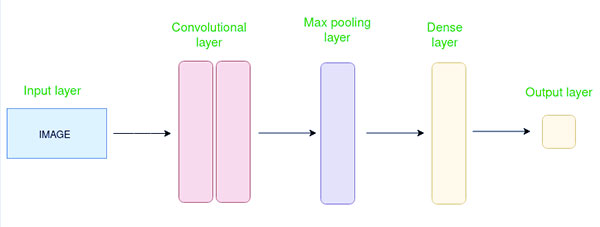
لایه Convolutional فیلترهایی را روی تصویر ورودی اعمال می کند تا ویژگی ها را استخراج کند، لایه Pooling تصویر را پایین می آورد تا محاسبات را کاهش دهد و لایه کاملاً متصل پیش بینی نهایی را انجام می دهد. شبکه فیلترهای بهینه را از طریق پس انتشار و نزول گرادیان می آموزد.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
لایه های کانولوشن چگونه کار می کنند؟
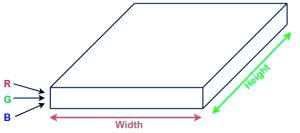
شبکه های عصبی کانولوشن یا covnet ها شبکه های عصبی هستند که پارامترهای خود را به اشتراک می گذارند. تصور کنید یک تصویر دارید. می توان آن را به صورت مکعبی با طول، عرض (بعد تصویر) و ارتفاع آن نشان داد (یعنی کانال به عنوان تصاویر عموما دارای کانال های قرمز، سبز و آبی است).
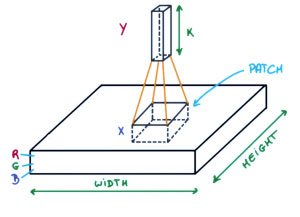
حال تصور کنید که یک پچ کوچک از این تصویر بگیرید و یک شبکه عصبی کوچک به نام فیلتر یا هسته را روی آن اجرا کنید، با خروجیهای K و نمایش عمودی آنها. اکنون آن شبکه عصبی را روی کل تصویر بکشید، در نتیجه، تصویر دیگری با عرض، ارتفاع و عمق متفاوت دریافت خواهیم کرد. به جای کانال های R، G و B، اکنون کانال های بیشتری داریم اما عرض و ارتفاع کمتری داریم. این عملیات Convolution نام دارد. اگر اندازه پچ با اندازه تصویر یکسان باشد، یک شبکه عصبی معمولی خواهد بود. به دلیل این پچ کوچک، وزن کمتری داریم.
بررسی اجمالی ریاضی کانولوشن
حالا بیایید در مورد کمی از ریاضیات صحبت کنیم که در کل فرآیند پیچیدگی دخیل است.
- لایههای کانولوشن شامل مجموعهای از فیلترها (یا هستههای) قابل یادگیری هستند که عرض و ارتفاع کوچک و عمقی مشابه حجم ورودی دارند (اگر لایه ورودی ورودی تصویر باشد 3).
- مثلاً اگر بخواهیم کانولوشن را روی تصویری با ابعاد 34*34*3 اجرا کنیم. اندازه ممکن فیلترها می تواند axax3 باشد، که در آن “a” می تواند چیزی شبیه به 3، 5 یا 7 باشد اما در مقایسه با بعد تصویر کوچکتر است.
- در طول پاس رو به جلو، هر فیلتر را به صورت گام به گام روی کل حجم ورودی بلغزانیم، جایی که هر مرحله گام نامیده می شود (که می تواند مقدار 2، 3 یا حتی 4 برای تصاویر با ابعاد بالا داشته باشد) و حاصل ضرب نقطه ای را بین وزن هسته و پچ از حجم ورودی.
- همانطور که فیلترهای خود را می کشیم، برای هر فیلتر یک خروجی دوبعدی دریافت می کنیم و در نتیجه آنها را روی هم قرار می دهیم، حجم خروجی با عمقی برابر با تعداد فیلترها را دریافت می کنیم. شبکه تمام فیلترها را یاد خواهد گرفت.
لایه های مورد استفاده برای ساخت ConvNets
یک معماری کامل شبکه های عصبی کانولوشن نیز به عنوان covnet شناخته می شود. covnet ها دنباله ای از لایه ها هستند و هر لایه از طریق یک تابع قابل تمایز یک حجم را به حجم دیگر تبدیل می کند.
انواع لایه ها: مجموعه داده ها
بیایید با اجرای یک کاور روی تصویر با ابعاد 32×32×3 مثالی بزنیم.
- لایه های ورودی: لایه ای است که در آن ورودی به مدل خود می دهیم. در CNN، به طور کلی، ورودی یک تصویر یا دنباله ای از تصاویر خواهد بود. این لایه ورودی خام تصویر را با عرض 32، ارتفاع 32 و عمق 3 نگه می دارد.
- لایه های Convolutional: این لایه ای است که برای استخراج ویژگی از مجموعه داده ورودی استفاده می شود. مجموعه ای از فیلترهای قابل یادگیری به نام هسته را در تصاویر ورودی اعمال می کند. فیلترها/هستهها ماتریسهای کوچکتری هستند که معمولاً به شکل ۲×۲، ۳×۳ یا ۵×۵ هستند. روی داده های تصویر ورودی می لغزد و محصول نقطه ای را بین وزن هسته و پچ تصویر ورودی مربوطه محاسبه می کند. خروجی این لایه به عنوان نقشه های ویژگی نامیده می شود. فرض کنید در مجموع از 12 فیلتر برای این لایه استفاده می کنیم، حجم خروجی به ابعاد 32 x 32 x 12 به دست می آید.
- لایه فعال سازی: با افزودن یک تابع فعال سازی به خروجی لایه قبلی، لایه های فعال سازی غیرخطی به شبکه اضافه می کنند. یک تابع فعالسازی از نظر عنصر را در خروجی لایه کانولوشن اعمال میکند. برخی از توابع فعال سازی رایج عبارتند از RELU: max(0، x)، Tanh، Leaky RELU، و غیره. حجم صدا بدون تغییر باقی می ماند، بنابراین حجم خروجی دارای ابعاد 32 x 32 x 12 خواهد بود.
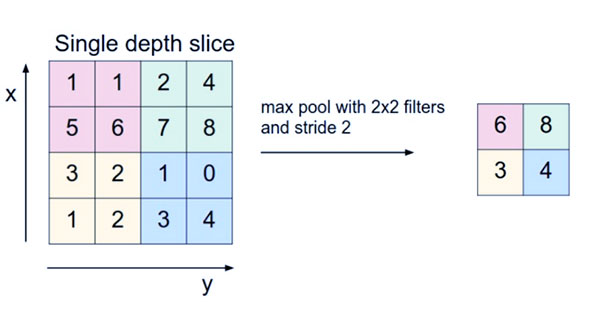
- لایه Pooling: این لایه به صورت دوره ای در covnet ها قرار می گیرد و وظیفه اصلی آن کاهش حجم است که باعث می شود محاسبات سریع باعث کاهش حافظه و همچنین جلوگیری از اضافه شدن حجم شود. دو نوع متداول لایه های ادغام عبارتند از: تجمع حداکثری و جمع آوری متوسط. اگر از یک استخر حداکثر با فیلترهای ۲×۲ و گام ۲ استفاده کنیم، حجم حاصل به ابعاد ۱۶×۱۶×۱۲ خواهد بود.
- Flattening: نقشههای ویژگی بهدستآمده پس از لایههای کانولوشن و ادغام به یک بردار یک بعدی مسطح میشوند تا بتوان آنها را به یک لایه کاملاً مرتبط برای طبقهبندی یا رگرسیون منتقل کرد.
- لایه های کاملاً متصل: ورودی لایه قبلی را می گیرد و وظیفه طبقه بندی یا رگرسیون نهایی را محاسبه می کند.

- لایه خروجی: خروجی از لایههای کاملاً متصل سپس به یک تابع لجستیک برای وظایف طبقهبندی مانند sigmoid یا softmax وارد میشود که خروجی هر کلاس را به امتیاز احتمال هر کلاس تبدیل میکند.
مثال: اعمال CNN بر روی یک تصویر
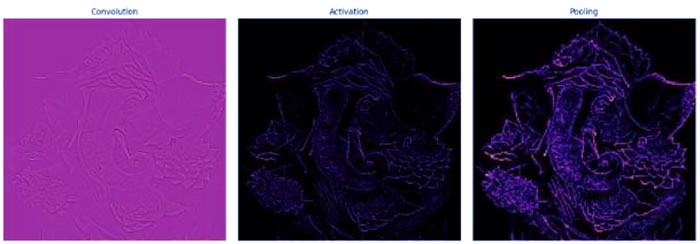
بیایید یک تصویر را در نظر بگیریم و لایه پیچشی، لایه فعال سازی و لایه ادغام را برای استخراج ویژگی داخلی اعمال کنیم.
تصویر ورودی:

مراحل:
- کتابخانه های لازم را وارد کنید
- پارامتر را تنظیم کنید
- کرنل را تعریف کنید
- تصویر را بارگذاری کنید و آن را رسم کنید.
- تصویر را دوباره فرمت کنید
- عملیات لایه پیچیدگی را اعمال کرده و تصویر خروجی را رسم کنید.
- عملیات لایه فعال سازی را اعمال کرده و تصویر خروجی را رسم کنید.
- عملیات لایه ادغام را اعمال کنید و تصویر خروجی را رسم کنید.
PYTHON

مزایا و معایب شبکه های عصبی کانولوشن (CNN)
مزایای CNN:
- در تشخیص الگوها و ویژگیها در تصاویر، ویدیوها و سیگنالهای صوتی خوب است.
- مقاوم در برابر ترجمه، چرخش و تغییر ناپذیری مقیاس.
- آموزش پایان به انتها، بدون نیاز به استخراج دستی ویژگی.
- می تواند حجم زیادی از داده ها را مدیریت کند و به دقت بالایی دست یابد.
معایب CNN:
- آموزش از نظر محاسباتی گران است و به حافظه زیادی نیاز دارد.
- اگر از داده های کافی یا تنظیم مناسب استفاده نشود، می تواند مستعد بیش از حد برازش باشد.
- به مقادیر زیادی از داده های برچسب دار نیاز دارد.
- تفسیرپذیری محدود است، درک آنچه شبکه آموخته است دشوار است.
مقاله های مرتبط:
1- زبان پرس و جو Neo4j Cypher چیست؟
2- تحلیل متن (Text Analytics) چیست و چگونه پایگاه های داده گراف می توانند کمک کنند ؟
3- کدام پایگاه داده برای یادگیری ماشینی بهتر است؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها