

زبان پرس و جو Neo4j Cypher چیست؟
درک یک پایگاه داده جدید و نحو همراه آن معمولاً یک چالش است و در مورد Neo4j Cypher تفاوتی ندارد. همانطور که گفته شد، Graphable این نمای کلی و معرفی Neo4j Cypher را ایجاد کرده است تا سفر را بسیار آسانتر کند.
Neo4j Cypher چیست؟
Neo4j Cypher زبان پرس و جو Neo4j است که دسترسی به Neo4j را از طریق عبارات اعلانی بسیار ساده تر می کند، بسیار شبیه به زبان SQL. ابتدا برای Neo4j ایجاد شد و اکنون بر اساس جنبش openCypher منبع باز که Neo4j شروع به استانداردسازی Graph Query Language کرد، از چیزی که به آن نحو هنری ASCII گفته می شود برای جستجوی داده ها در پایگاه داده گراف استفاده می کند.
آیا از قبل SQL را می شناسید؟ ببینید Neo4j Cypher چگونه شبیه و متفاوت است
به عنوان روشی برای جستجوی داده ها از پایگاه داده گراف، رفتار پرس و جو Neo4j Cypher شباهت های زیادی با SQL دارد و مانند SQL به عنوان یک زبان پرس و جوی ساختاریافته، مبتنی بر متن طبقه بندی می شود. از آنجایی که هر دو از کلمات کلیدی، جملات و عبارات شامل توابع و محمول تشکیل شدهاند، بسیاری از نحو به نظر آشنا خواهد بود (به عنوان مثال p.ProductId = 3365، WHERE، ORDER BY، LIMIT، و غیره). با این حال، از آنجایی که Neo4j Cypher در مورد بیان الگوهای گراف است، تفاوت های مهمی نیز وجود دارد که عمدتاً ناشی از این واقعیت است که Neo4j یک پایگاه داده بدون طرح واره است.
پایگاه های داده طرحواره ای تأیید نتایج پرس و جو را حتی مهم تر می کند
برخی از مهم ترین تفاوت های ناشی از پارادایم پایگاه داده بدون طرحواره را می توان در سه گروه اصلی طبقه بندی کرد که در زیر به آنها اشاره شده است:
۱- جستارهای Neo4j Cypher می توانند به چیزهایی اشاره کنند که حتی وجود ندارند. در حالی که بیشتر زبان های پرس و جو اگر بخواهید به جدول یا ستونی که در طرحواره وجود ندارد ارجاع دهید با خطا مواجه می شوند، Neo4j Cypher این کار را نمی کند. این می تواند به دلیل دشواری بیشتر در اشکال زدایی نتایج نگران کننده باشد.
در SQL، اگر هیچ نتیجه ای برگردانده نشد، به این دلیل است که هیچ داده ای وجود ندارد که با پرس و جو شما مطابقت داشته باشد، اما در Neo4j Cypher، ممکن است به دلیل غلط املایی (یا missing) برچسب های Node، انواع رابطه یا ویژگی باشد. این به این دلیل است که Neo4j Cypher در تلاش است تا الگوها را مطابقت دهد، اگر الگوی وجود نداشته باشد، چیزی برگردانده نمی شود.
SQL:
SELECT alias.Property_a, alias.Property_b
FROM Persssson as alias -- misspelled Table Name
LIMIT 1;
>> ERROR Unknown table 'Persssson'
Cypher:
MATCH (alias:Persssson) // misspelled Label
RETURN alias.Property_a, alias.Property_b
LIMIT 1;
>> NULL, NULL
فروش کرک تبلو
۲- سینتکس او برای دسترسی به خصوصیات برای خصوصیات غیرموجود همانند خواص بدون مقدار است. در اینجا یک مثال Neo4j Cypher است که این رفتار متفاوت را نشان می دهد:
MATCH (alias:Person)
RETURN alias.unset_property, alias.set_property, alias.fake_property
LIMIT 1;
>> NULL, “prop value”, NULL
۳– انواع ویژگی های ذخیره شده در گره ها کاملاً ad-hoc هستند.
به عنوان مثال، چندین گره با برچسب “Person” می توانند ویژگی های کاملا متفاوتی از انواع داده های مختلف داشته باشند. هنگام پرس و جو از آنها، یک مقدار در صورت وجود، یا NULL اگر تنظیم نشده باشد یا وجود نداشته باشد، برگردانده می شود.
MATCH (p:Person) RETURN p.property1, p.age, p.email LIMIT 4;
این سه ویژگی را برای هر گره برمیگرداند، اما نوع دادهها ممکن است متفاوت باشد و میتواند به شکل زیر باشد:

۴- جهت ارتباط در Cypher چیزی کاملا متفاوت را انجام می دهد.
در SQL هنگام پیوستن به دو جدول، اتصالات بسیار رایج، اتصالات LEFT/RIGHT هستند که مجموعه نتایج مورد نظر شما را تعریف می کنند. در Neo4j Cypher مسیرهای ارتباط همه چیز در مورد تطبیق الگو است.
تفاوت اصلی از این واقعیت ناشی می شود که آنها معادل نیستند.
MATCH (person1:Person)-[:HEARD_OF]->(person2:Person)
یکسان نیست
MATCH (person1:Person)<-[:HEARD_OF]-(person2:Person)
حذف جهت رابطه کارایی کمتری دارد، اما در جایی که هر یک از جهت های رابطه وجود دارد، داده ها را برمی گرداند.
MATCH (person1:Person)–[:HEARD_OF]-(person2:Person)
Neo4j Cypher، یک زبان پرس و جو گراف
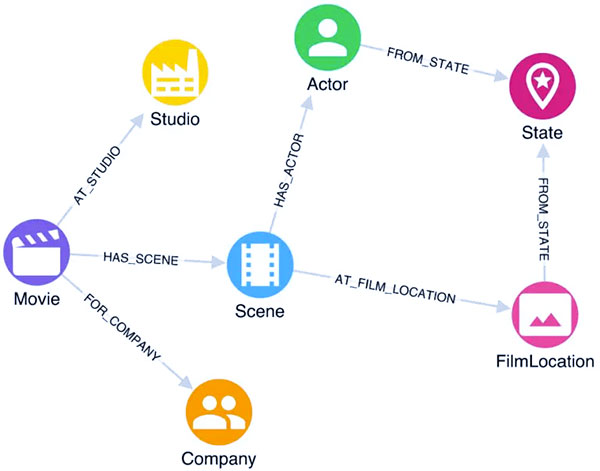
بیایید از بالاترین سطح با مروری بر ساختار یک پایگاه داده گراف متشکل از گره ها و روابط بین آنها شروع کنیم. گره ها معمولا دارای برچسب هایی هستند که برای تعیین نوع آنها استفاده می شود. به زبان ساده، میتوانید یک Node را به عنوان یک ردیف از دادهها در نظر بگیرید که Label نام جدول است. زبان پرس و جو Cypher این را با نمادهایی بیان می کند که مستقیماً در نحو زبان گنجانده شده است. این کار خواندن یک پرس و جو را حتی برای کاربران تازه کار آسان می کند.
مرحله 1: خود را با SYNTAX اولیه آشنا کنید
Node ها با پرانتز احاطه شده اند و حاوی node Label و alias (نام مستعار) آن هستند.
(node_alias:NodeLabel)
روابط با براکت های مربع احاطه شده اند و حاوی رابطه نوع مستعار آن هستند.
[relationship_alias:RELATIONSHIP_TYPE]
Node ها و روابط با خط تیره و نماد بزرگتر/کوچکتر به هم مرتبط می شوند تا جهت رابطه را نشان دهند.
(person1:Person)-[rel1:HEARD_OF]->(person2:Person)
CREATE (person1:Person {property1: “a string”, property2: 123});
CREATE (person1:Person)-[rel:HEARD_OF {property1: DATE()}]->(person2:Person);
CREATE (person2:Person {property1:[“element1”, “element2”]});
MATCH (person1:Person) SET person1.property1 = "a different string";مرحله 2: دستورات کلیدواژه CYPHER NEO4HJ را درک کنید
مانند هر زبان پرس و جو، دستورات زیادی در قالب کلمات کلیدی رزرو شده و ترکیب کلمات کلیدی برای انجام اقدامات مختلف وجود دارد. برخی از موارد رایج در Cypher عبارتند از MATCH, CREATE, WHERE, SET, RETURN, WITH که نشان دهنده پرکاربردترین آنهاست. ممکن است این برگه تقلب Neo4j cypher برای شما مفید باشد.
مرحله 3: بهترین شیوه های ترکیب رمزی NEO4J اساسی ترین را هضم کنید
در زمینه Neo4j، خود interpreter اهمیتی نمیدهد که چگونه درخواست خود را بنویسید تا زمانی که از الگوهای مناسبی مانند اطراف گرهها با () و روابط با [] و غیره پیروی کنید.
با این حال، برخی از بهترین شیوههای syntax وجود دارد که به شدت توسط جامعه توصیه میشوند، که به سازگاری کمک میکنند و خواندن پرس و جو را آسانتر میکنند.
- برچسب های Node در PascalCase هستند
- انواع رابطه در MACRO_CASE هستند
این شیوهها از قرارداد جاوا برای نامهای کلاس (یک node) و ثابت (یک رابطه) پیروی میکنند.
قراردادهای نام های دارایی و نام مستعار node/رابطه معمولاً به چارچوبی که در آن از پرس و جوها استفاده می کنید بستگی دارد. در پایتون، استفاده از snake_case برای این موارد رایجتر است، در حالی که در NodeJS camelCase معمول است.
مرحله 4: درک NEO4J CYPHER CASE SENSITIVITY
این ساده اما مهم است: nodeها، روابط، ویژگیها و مقادیر ویژگی همگی به حروف بزرگ و کوچک حساس هستند، فقط دستورات کلیدواژه حساس نیستند.
یک node با برچسبی مانند “Person” از کلاس متفاوتی نسبت به node با برچسبی مانند “person” است. همین امر در مورد روابط و انواع آنها صدق می کند.
(person_alias:Person) ≠ (person_alias:person)
()-[:HEARD_OF]->() ≠ ()-[:heard_of]->()
اگرچه هر دو مثال بالا توسط interpreter پذیرفته شده است، آنها معادل نیستند و به دو نوع مختلف Node/روابط اشاره دارند، و ویژگی های گره از همین منطق پیروی می کنند.
چرا از Cypher و Neo4j استفاده کنیم؟
مقاله های مرتبط:
1- توسعه پایگاه داده استاندارد SQL Server
2- چگونه با SQL از ابزار Tableau خود اطلاعات بیشتری کسب کنید
3- کدام پایگاه داده برای یادگیری ماشینی بهتر است؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها