

پایگاه داده گراف (Graph Database) چیست؟
بهعنوان یک توسعهدهنده یا تحلیلگر پایگاه داده، ممکن است نام «پایگاههای اطلاعاتی نمودار یا گراف» را شنیده باشید، اما شاید دقیقاً ندانید که آنها چیست یا چگونه از آنها استفاده کنید. در این مقاله ما به اشتراک میگذاریم که پایگاهداده گراف به همراه برخی موارد استفاده، و همچنین اینکه چگونه پایگاههای داده گراف میتوانند ارزش ایجاد کنند، به اشتراک میگذاریم.
پایگاه داده گراف (Graph Database) چیست؟
به زبان ساده، پایگاه داده گراف، پایگاه داده ای است که به گونه ای طراحی شده است که ارتباطات بین داده ها به اندازه خود داده ها مهم در نظر گرفته شود. همچنین داده ها را به گونه ای انعطاف پذیر ذخیره می کند که محدود به یک مدل صلب موجود نباشد. دادهها در پایگاه داده نگهداری میشوند مانند آنچه که میبینید آنها را روی یک تخته سفید میبینید – به وضوح هر موجودیت و نحوه «ارتباط» یا اتصال آن به موجودیتهای دیگر را نشان میدهد.
مانند هر سیستم پایگاه داده دیگری، پایگاه داده های گراف (مانند Neo4j) ذخیره سازی و بازیابی کارآمد داده ها را برای پشتیبانی از کاربردهای مختلف تسهیل می کند. مانند پایگاه داده RDBMS از لحاظ تاریخی محبوب، پایگاه داده های گراف نیز راهی را برای سازماندهی مداوم و سیستماتیک داده ها برای پشتیبانی از سؤالات، دانش خاص دامنه و برنامه های کاربردی منحصر به فرد که در هسته هر سازمان قرار دارند، ارائه می دهند.
با این حال، نحوه ذخیره و بازیابی آن داده ها است که اساساً پایگاه های داده گراف را از سایر سیستم های سنتی RDBMS مبتنی بر SQL متمایز می کند. و با بررسی آن تفاوتها است که میتواند روشن کند که دقیقاً چه چیزی پایگاههای داده گراف را از بسیاری دیگر از گزینههای ذخیرهسازی دادهای که امروزه استفاده میشود متمایز میکند.
چرا از پایگاه داده های نموداری یا گراف استفاده کنیم؟
اساسی ترین جنبه یک پایگاه داده گراف برای درک، ساختار داده ای است که از آن برای ذخیره داده ها استفاده می کند که گراف نامیده می شود.
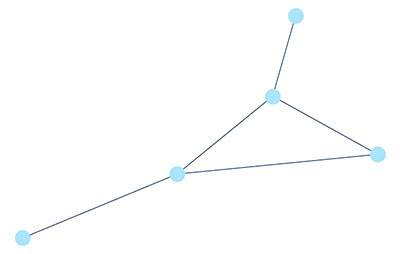
نمودارها متشکل از مجموعهای از گرهها که توسط روابط یا لبهها به هم متصل شدهاند، به دلیل توانایی آنها در توصیف بهینهتر پیچیدگی اتصالات طبیعی در جهان، برای دههها و در ریاضیات برای قرنها ساختاری اساسی در علوم کامپیوتر بودهاند. از آنجایی که نمودارها مانند مغز انسان، دادهها را ذخیره میکنند – با اتصال مفاهیم به یکدیگر از طریق روابط بین آنها، آنها رسانه بصری تری برای ذخیره، تجزیه و تحلیل و درک دادهها از طریق لنز این ارتباطات ارائه میدهند.
جای تعجب نیست که این ارتباطات طبیعی ارزشمند در همه جای داده های ما وجود دارد. با بهرهگیری از این واقعیت با یک ذخیرهگاه دادههای بومی که این ارتباط ذاتی را در دادههای ما جای میدهد، پایگاههای اطلاعاتی گراف میتوانند دادههای ما را در مقیاس، با تمرکز ویژه بر حفظ اطلاعات و الگوهای منحصربهفرد با ارزش و ذاتاً به هم مرتبط موجود در داخل، ذخیره کنند. این مثال ساده زیر بینش بصری بیشتری را در مورد آن مقدار ارائه می دهد
یک پایگاه داده گراف چگونه متفاوت است؟
مجموعه داده سنتی جدولی زیر را در نظر بگیرید:
| Name | Job | Address |
| Sonya | Pilot | 101 N Main St |
| Parker | Food Service | 101 N Main St |
| Alex | Pilot | 455 West Ave |
برای اهداف ساده نگهداری سوابق و جستجوها، این ساختار جدولی سطرها و ستونها به خوبی کار می کند (همانطور که توسط فروشگاه های داده کلاسیک RDBMS مانند Microsoft SQL Server و MySQL و غیره استفاده می شود). اگر بخواهیم سؤالی مانند “سونیا کجا زندگی می کند” بپرسیم؟ سپس رسیدن به پاسخ ساده است. ما به سادگی روی رکورد سونیا خود جستجو می کنیم، ستون “آدرس” را بررسی می کنیم و پاسخ خود را داریم. با این حال، اگر بخواهیم یک سوال ذاتاً مرتبط تری بپرسیم، مانند “چه کسی در آدرس سونیا زندگی می کند؟” هنگام استفاده از قالبهای سنتی جدولی برای پاسخگویی به این نوع سؤالات، با چالش مقیاسبندی مواجه میشویم.
برای پاسخ به این موضوع از یک فروشگاه داده های جدولی، ابتدا باید مانند قبل در رکورد سونیا خود جستجو کنیم، آدرس آنها را بگیریم، و سپس جستجوی دیگری را بر اساس این آدرس انجام دهیم تا پاسخی دریافت کنیم. و در حالی که این ممکن است در چارچوب مثال سادهای مانند این، اضافهای بیاهمیت به نظر برسد، پیچیدگی و منابع محاسباتی مورد نیاز در مقیاس سازمانی میتواند به سرعت پرسیدن این نوع سؤالات مهم به هم پیوسته را غیرقابل دفاع کند – به ویژه هنگامی که اتصالات بیشتری اضافه میکنیم و بیشتر میپرسیم.
نمونه پایگاه داده نموداری یا گراف
بیایید از منظر یک نمودار به این موضوع نگاه کنیم. برای ساختار این داده ها به عنوان یک نمودار، ما به سادگی تمام موجودیت های متمایز در داده ها را استخراج می کنیم و آنها را به عنوان گره ها در نظر می گیریم:
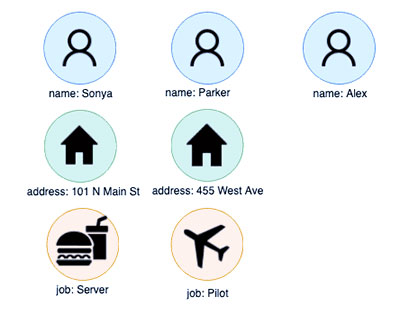
گاهی اوقات، این کار به سادگی جمع آوری مقادیر منحصر به فرد از هر ستون است. با این حال، برای دادههای ساختاریافتهتر مانند رشتههای آدرس خام، ایمیلها یا نامهای شرکت، این فرآیند میتواند به آمادهسازی دادههای اضافی از طریق فرآیند حل و فصل موجودیت نیاز داشته باشد، که اغلب یکی از اولین چیزهایی است که کاربران هنگام استفاده از نمودارها برای اولین بار از آن عبور میکنند.
به همین ترتیب، با استفاده از تکنیکهای مدرن پردازش زبان طبیعی (NLP)، پایگاههای اطلاعاتی گراف حتی یک مناسب مقیاسپذیر منحصربهفرد برای هدایت ارزش بالقوه از مقدار انبوه دادههای غیرساختار نشده معمولاً بدون اهرم در سازمان هستند (به عنوان مثال، نظرات مشتریان، متن رسانههای اجتماعی). ، مستندات محصول، توضیحات فهرست، پایگاه های دانش داخلی، قوانین خارجی و غیره)، که ماهیت آن نیز بسیار مرتبط است.
پس از این مرحله از استخراج موجودیتهای منحصر به فرد، با تعیین نوع رابطه بین گرهها، روابط یا لبههایی را بین گرههایی که با آن رکورد مشترک هستند ایجاد میکنیم. این به ما این امکان را میدهد که نه تنها واقعیت مرتبط بودن دو گره را ذخیره کنیم، بلکه نحوه ارتباط دو گره را نیز ذخیره کنیم که ماهیت متصل دادهها را بیشتر به تصویر میکشد و ما را قادر میسازد که اکنون با استفاده از اطلاعات ذخیرهشده، عملیات دشوار، اگر قبلا غیرممکن نبوده، انجام دهیم. در آن روابط با انجام این کار نمودار زیر را به ما می دهد:
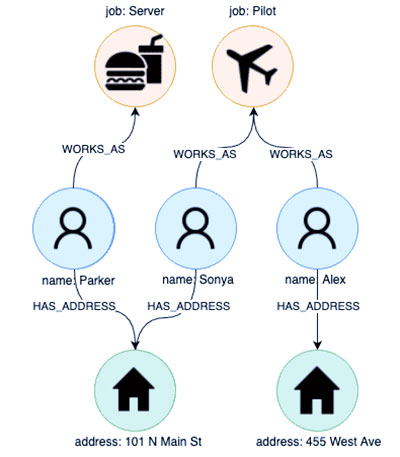
کرک تبلو
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
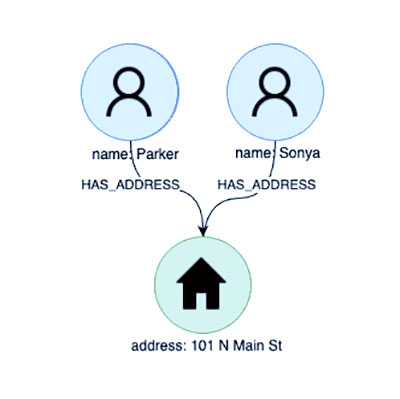
اکنون سؤال قبلی ما را به یاد بیاورید “چه کسی در آدرس سونیا زندگی می کند؟” با توجه به اینکه داده های ما اکنون به صورت نموداری ساختار یافته و ذخیره شده اند، این سوال بسیار ساده است. با جستجوی گره ای که نشان دهنده سونیا است، رکورد مورد نظر خود را تعیین می کنیم:

پس از تعیین مکان گره مورد نظر، یافتن رکورد آدرس آنها به سادگی یک پیمایش سریع از طریق رابطه / نحو HAS_ADDRESS است:
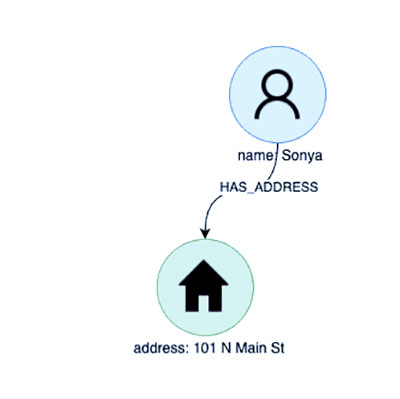
اکنون برای رسیدن به پاسخ نهایی به سوال خود، فقط باید تمام روابط HAS_ADDRESS دیگر که به گره آدرس متصل هستند را دنبال کنیم. انجام این کار به سرعت همه رکوردهای مجاور را بدون نیاز به جستجوی اضافی مکان یابی می کند و زمان و پیچیدگی پرس و جو ما را کاهش می دهد.
فروش کرک Tableau
با استفاده از ماهیت طبیعی بهم پیوسته نمودارها به عنوان یک ساختار داده، ما میتوانیم از پرسیدن سؤالات خود با یک سری جستجوی SQL گران قیمت و اغلب پیچیده در بسیاری از ردیفها و ستونهای دادههای ذخیرهشده سخت، به یک سری پیمایش ساده با استفاده از برخی از دادهها تبدیل شویم. طعم یک زبان پرس و جو گراف (مانند Cypher، Gremlin و غیره) در میان دادههایی که مجاورت آنها است.
به عنوان یک راه با سرعت بالا برای رسیدن به پاسخ به سؤالات پیچیده مرتبط ما عمل میکند. و در حالی که نمودارها و نظریه گراف ها برای سال ها توسط ریاضیدانان و دانشمندان رایانه برای حل تعدادی از سؤالات مرتبط به هم مانند این مورد استفاده قرار گرفته است، تنها در دهه گذشته است که ما شاهد استفاده از این ساختارهای داده قدرتمند به عنوان ستون فقرات هدفمند بوده ایم. پایگاههای دادهای که اکنون ذخیرهسازی مقیاسپذیر و بازیابی دادههای به هم پیوسته را در کسبوکارها نیرو میدهند.
مقاله های مرتبط:
1- انواع پایگاه های داده (Database)
2- پایگاه های داده یکپارچه سازی در NoSQL چیست؟
3- کدام پایگاه داده برای یادگیری ماشینی بهتر است؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها