

داده کاوی با Orange
Orange یک شیء اصلی و کتابخانه روتین C++ است که طیف گسترده ای از الگوریتم های یادگیری ماشین و داده کاوی استاندارد و غیر استاندارد را در خود جای داده است. این یک ابزار تجسم داده، داده کاوی و یادگیری ماشین منبع باز است. Orange یک محیط قابل اسکریپت برای نمونه سازی سریع جدیدترین الگوریتم ها و الگوهای آزمایشی است. این مجموعه ای از ماژول های مبتنی بر پایتون است که در کتابخانه هسته وجود دارد. برخی از عملکردها را پیاده سازی می کند که زمان اجرا برای آنها ضروری نیست و این در پایتون انجام می شود.
این شامل انواع وظایف مانند چاپ زیبای درختان تصمیم، بسته بندی و تقویت، زیرمجموعه ویژگی ها و بسیاری موارد دیگر است. Orange مجموعهای از ویجتهای گرافیکی است که از استراتژیهای کتابخانه هسته و ماژولهای Orange استفاده میکند و رابط کاربری مناسبی را ارائه میدهد. ویجت از ارتباطات مبتنی بر دیجیتال پشتیبانی می کند و می تواند توسط یک ابزار برنامه نویسی بصری به نام orange canvas در یک برنامه کاربردی جمع آوری شود.
←برای خرید کرک لایسنس تبلو Tableau با تمام ویژگی ها کلیک کنید
فروش کرک تبلو

همه اینها با هم یکOrange را به یک الگوریتم انحصاری مبتنی بر مؤلفه برای داده کاوی و یادگیری ماشین تبدیل می کند. Orange هم برای کاربران باتجربه و هم برای تحلیلگران در داده کاوی و یادگیری ماشینی پیشنهاد شده است که می خواهند الگوریتم های خود را با استفاده مجدد از حداکثر کد ممکن ایجاد و آزمایش کنند، و برای کسانی که به سادگی وارد این زمینه می شوند و می توانند محتوای کوتاه پایتون برای داده ها بنویسند. تجزیه و تحلیل
هدفOrange فراهم کردن بستری برای انتخاب مبتنی بر آزمایش، مدلسازی پیشبینیکننده و سیستم توصیه است. این در درجه اول در بیوانفورماتیک، تحقیقات ژنومی، زیست پزشکی و آموزش استفاده می شود. در آموزش، برای ارائه روشهای آموزشی بهتر برای دادهکاوی و یادگیری ماشینی به دانشجویان زیستشناسی، زیستپزشکی و انفورماتیک استفاده میشود.
داده کاوی با Orange
Orange از یک دامنه انعطاف پذیر برای توسعه دهندگان، تحلیلگران و متخصصان داده کاوی پشتیبانی می کند. Python، یک زبان برنامه نویسی نسل جدید و محیط برنامه نویسی، که در آن اسکریپت های داده کاوی ما ممکن است آسان اما قدرتمند باشند. Orangeاز یک رویکرد مبتنی بر مولفه برای نمونه سازی سریع استفاده می کند. ما می توانیم تکنیک تجزیه و تحلیل خود را به سادگی مانند قرار دادن آجرهای لگو پیاده سازی کنیم یا حتی از یک الگوریتم موجود استفاده کنیم.
اجزای Orangeبرای برنامه نویسی ویجت های Orangeبرای برنامه نویسی بصری چیست؟ ویجت ها از یک مکانیسم ارتباطی طراحی شده ویژه برای عبور اشیایی مانند طبقه بندی کننده ها، رگرسیورها، لیست های ویژگی ها و مجموعه داده ها استفاده می کنند که امکان ساخت آسان طرح های داده کاوی نسبتاً پیچیده را فراهم می کند که از روش ها و تکنیک های مدرن استفاده می کنند.
ابزارOrange
اشیاء هسته Orange و ماژول های پایتون وظایف داده کاوی متعددی را در خود جای داده اند که دور از پیش پردازش داده ها برای ارزیابی و مدل سازی هستند. اصل عملکردOrange ، تکنیک های پوششی و دیدگاه در داده کاوی و یادگیری ماشین است. به عنوان مثال، درخت تصمیم گیری از بالا به پایینOrange، تکنیکی است که از اجزای متعددی ساخته شده است که هر کسی می تواند نمونه اولیه آن را در پایتون ساخته و به جای نمونه اصلی استفاده کند.
ویجتهای Orange صرفاً اشیاء گرافیکی نیستند که یک رابط گرافیکی برای یک استراتژی خاص در Orange ایجاد میکنند، بلکه شامل یک مکانیسم سیگنالدهی قابل انطباق است که برای برقراری ارتباط و تبادل اشیایی مانند مجموعه دادهها، مدلهای طبقهبندی، یادگیرندگان، اشیایی است که نتایج را ذخیره میکند. ارزیابی همه این ایده ها قابل توجه هستند و با هم Orange را از دیگر ساختارهای داده کاوی تشخیص می دهند.
ابزارک های Orange:
ویجت های Orange به ما یک رابط کاربری گرافیکی برای داده کاوی و تکنیک های یادگیری ماشینیOrange می دهند. آنها ویجت هایی را برای ورود و پیش پردازش داده ها، طبقه بندی، رگرسیون، قوانین مرتبط و خوشه بندی مجموعه ای از ویجت ها برای ارزیابی مدل و تجسم نتایج ارزیابی، و ویجت هایی برای صادرات مدل ها به PMML ترکیب می کنند.
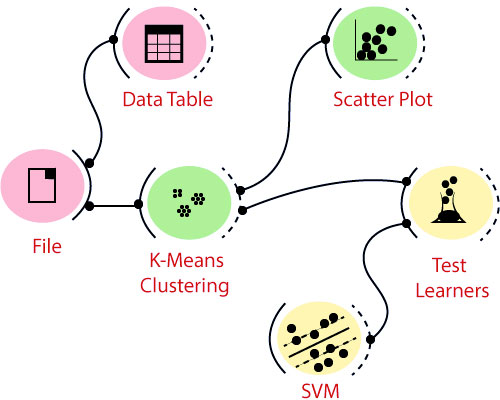
ویجت ها داده ها را با توکن هایی که از فرستنده به ویجت گیرنده ارسال می شود، منتقل می کنند. به عنوان مثال، یک ویجت فایل، اشیاء داده را خروجی می دهد، که می تواند توسط ویجت یادگیرنده درخت طبقه بندی ویجت دریافت شود. درخت طبقه بندی یک مدل طبقه بندی می سازد که داده ها را به ویجتی ارسال می کند که درخت را به صورت گرافیکی نشان می دهد. یک ویجت ارزیابی ممکن است یک مجموعه داده از ویجت فایل و اشیاء دریافت کند.
اسکریپت Orange:
اگر میخواهیم به اشیاء Orange دسترسی داشته باشیم، باید اجزای خود را بنویسیم و طرحهای آزمایشی و برنامههای یادگیری ماشین خود را از طریق اسکریپت طراحی کنیم. رابط های Orangeبه پایتون، مدلی ساده برای استفاده از یک زبان برنامه نویسی با نحو واضح و قدرتمند و مجموعه وسیعی از کتابخانه های اضافی. مانند هر زبان برنامه نویسی، پایتون می تواند برای آزمایش چند ایده به صورت متقابل یا برای توسعه اسکریپت ها و برنامه های دقیق تر استفاده شود.
با مثالی میتوانیم نحوه استفاده از Python و Orangeرا ببینیم، یک اسکریپت آسان را در نظر بگیریم که مجموعه دادهها را میخواند و تعداد ویژگیهای استفاده شده را چاپ میکند. ما از مجموعه داده های طبقه بندی به نام “رای گیری” از مخزن یادگیری ماشین UCI استفاده خواهیم کرد که شانزده رای کلیدی هر یک از نمایندگان پارلمان هند (عضو پارلمان) را ثبت می کند و هر نماینده را با یک عضویت حزب برچسب گذاری می کند.
import orange
data1 = orange.ExampleTable(‘voting.tab’)
print(‘Instance:’, len(data1))
print(Attributes:’, 1len(data.domain.attributes))
در اینجا، میتوانیم ببینیم که اسکریپت ابتدا در کتابخانه Orange بارگیری میشود، فایل داده را میخواند و آنچه را که نگرانش بودیم چاپ میکند. اگر این اسکریپت را در script.py ذخیره کنیم و آن را با دستور پوسته “python script.py” اجرا کنیم، مطمئن شویم که فایل داده در همان دایرکتوری است، دریافت می کنیم
Instances: 543
Attributes: 16
اجازه دهید اسکریپت خود را ادامه دهیم که از همان داده های ایجاد شده توسط یک طبقه بندی کننده ساده بیزی استفاده می کند و طبقه بندی پنج نمونه اول را چاپ می کنیم:
model = orange.BayesLearner(data1)
for i in range(5):
print(model(data1[i]))
فروش لایسنس Tableau
تولید مدل طبقه بندی آسان است. ما شیء Orangeرا فراخوانی کرده ایم (Bayes Learner) و مجموعه داده را به آن داده ایم. هنگامی که یک نمونه، برچسب کلاس ممکن را برمی گرداند، شی دیگری (طبقه بندی کننده بیزی ساده) را برمی گرداند. در اینجا می توانیم خروجی این قسمت از اسکریپت را مشاهده کنیم:
inc
inc
inc
bjp
bjp
در اینجا، ما باید کشف کنیم که طبقه بندی صحیح چه بوده است. ما می توانیم برچسب های اصلی پنج نمونه خود را چاپ کنیم:
for i in range(5):
print(model(data1[i])), ‘originally’ , data[i].getclass()
آنچه ما پوشش می دهیم این است که طبقه بندی کننده ساده بیزی نمونه سوم را اشتباه طبقه بندی کرده است:
inc originally inc
inc originally inc
inc originally bjp
bjp originally bjp
bjp originally bjp
همه طبقهبندیکنندههای اجرا شده درOrange احتمالی هستند. به عنوان مثال، آنها احتمالات کلاس را فرض می کنند. بنابراین در طبقهبندی بیزی ساده، و ممکن است نگران این باشیم که در مورد سوم چقدر از دست دادهایم:
n = model(data1[2], orange.GetProbabilities)
print data,domain.classVar.values[0], ‘:’, n[0]
در اینجا متوجه میشویم که شاخصهای پایتون با 0 شروع میشوند، و زمانی که یک طبقهبندی کننده با آرگومان Orange فراخوانی میشود، مدل طبقهبندی یک بردار احتمال را برمیگرداند.-Getprobabilities. مدل ما احتمال بسیار بالایی را برای یک inc تخمین زد:
Inc : 0.878529638542
نتیجه گیری
Orange یک پلت فرم قدرتمند برای انجام تجزیه و تحلیل و تجسم داده ها، دیدن جریان داده ها و بهره وری بیشتر است. این یک پلت فرم منبع باز و تمیز و امکان افزودن قابلیت های بیشتر برای همه زمینه های علم را فراهم می کند.
مقاله های مرتبط:
1- معرفی انواع مدل های داده ای یا Data Model
2- معرفی 10 ابزار برتر برای تجزیه و تحلیل کسب و کار
3- Tableau برای چه مواردی استفاده می شود ؟
4-داشبورد سازی در نرم افزار تبلو و تجسم داده ها